
The goal of the MPAI Multimodal Conversation (MPAI-MMC) standard is to enable forms of human-machine conversation that emulate the human-human one in completeness and intensity. While this is clearly a long-term goal, MPAI is focusing on standards providing frameworks which break down – where possible – complex AI functions to facilitate the formation of a component market where solution aggregators can find AI Modules (called AIM) to build AI Workflows (called AIW) corresponding to standard use cases. The AI Framework standard (MPAI-AIF) is a key enabler of this plan.
In September 2021, MPAI approved Multimodal Conversation V1 with 5 use cases. The first one – Conversation with Emotion – assumes that a human converses with a machine that understands what the human says, extracts the human’s emotion from their speech and face, articulates a textual response with an attached emotion, and converts it into synthetic speech containing emotion and a video containing a face expressing the machine’s emotion whose lips are properly animated.
The second MPAI-MMC V1 use case was Multimodal Question Answering. Here a human asks a question to a machine about an object. The machine understands the question and the nature of the object and generates a text answer which is converted to synthetic speech.
The other use cases are about automatic speech translation and they are not relevant for this article.
In July 2022, MPAI issued a Call for Technologies with the goal to acquire the technologies needed to implement three more Multimodal Conversation use cases. One concerns the extension of the notion of “emotion” to “Personal Status”, an element of the internal state of a person which also contains cognitive status (what a human or a machine has understood about the context) and attitude (what is the stance the human or the machine intends to adopt in the context). Personal status is conveyed by text, speech, face, and gesture. See here for more details. Gesture is the second ambition of MPAI-MMC V2.
A use case of MPAI-MMC V2 is “Conversation about a Scene” and can be described as follows:
A human converses with a machine indicating the object of their interest. The machine sees the scene and hears the human; extracts and understands the text from the human’s speech and the personal status in their speech, face, and gesture; understands the object intended by the human; produces a response (text) with its own personal status; and manifests itself as a speaking avatar.
Figure 1 depicts a subset of the technologies that MPAI needs in order to implement this use case.
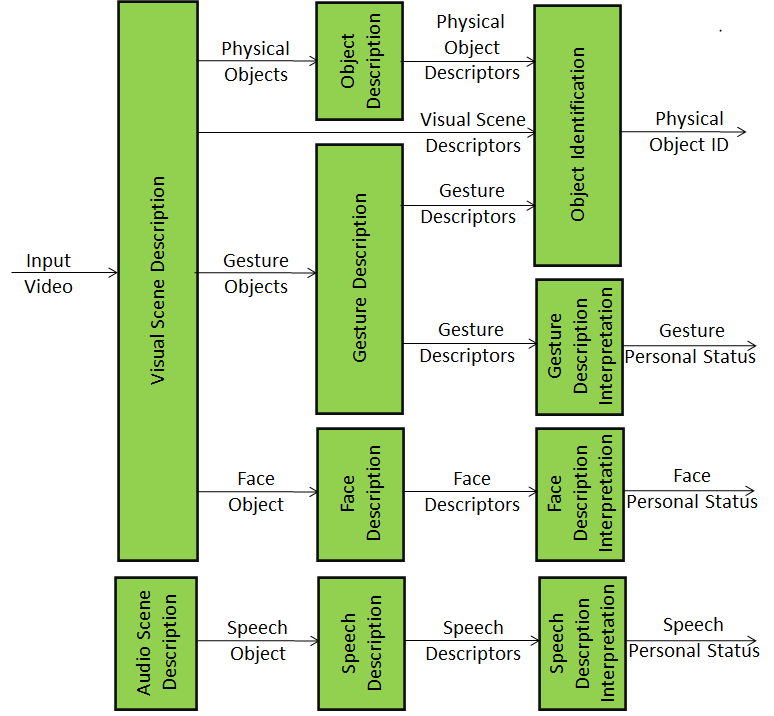
Figure 1 – The audio-visual front end
These are the functions of the modules and the data provided:
- The Visual Scene Description module analyses the video signal, describes, and makes available the Gesture and the Physical Objects in the scene.
- The Object Description module provides the Physical Object Descriptors.
- The Gesture Description modules provides the Gesture Descriptors.
- The Object Identification module uses both Physical Object Descriptors and Visual Scene-related Descriptors, to understand which object in the scene the human points their finger to, select the appropriate set of Physical Object Descriptors, and give the Object ID.
- The Gesture Descriptor Interpretation module uses the Gesture Descriptors to extract the Personal Status of Gesture.
- The Face Description – Face Descriptor Interpretation chain produces the Personal Status of Face.
- The Audio Scene Description module analyses the audio signal, describes, and makes available the Speech Object.
- The Speech Description – Speech Descriptor Interpretation chain produces the Personal Status of Speech.
After the “front end” part we have a “conversation and manifestation” part involving another set of technologies as described in Figure 2.
![]()
![]()
Figure 2 – Conversation and Manifestation
- The Text and Meaning Extraction module produces Text and Meaning.
- The Personal Status Fusion module integrates the three sources of Personal Status into the Personal Status.
- The Question and Dialogue Processing module processes Input Text, Meaning, Personal Status and Object ID and provides the Machine Output Text and Personal Status.
- The Personal Status Display module processes Machine Output Text and Personal Status and produces a speaking avatar uttering Machine Speech and showing an animated Machine Face and Machine Gesture.
The MPAI-MMC V2 Call considers another use case – Avatar-Based Videoconference – that uses avatars in a different way.
Avatars representing geographically separated humans participate in a virtual conference. Each participant receives each other participants’ avatars, locates them around a table, and participates in the videoconference embodied in their own avatar.
The system is composed of:
- Transmitter client: Extracts speech and face descriptors for authentication, creates avatar descriptors using Face & Gesture Descriptors, and Meaning, and sends the participant’s Avatar Model & Descriptors and Speech to the Server.
- Server: Authenticates participants; distributes Avatar Models & Descriptors and Speech of each participant.
- Virtual Secretary: Makes and displays a summary of the avatars’ utterances using their speech and Personal Status.
- Receiver client: Creates virtual videoconference scene, attaches speech to each avatar and lets participant view and/or navigate the virtual videoconference room.
Figure 3 gives a simplified one-figure description of the use case.
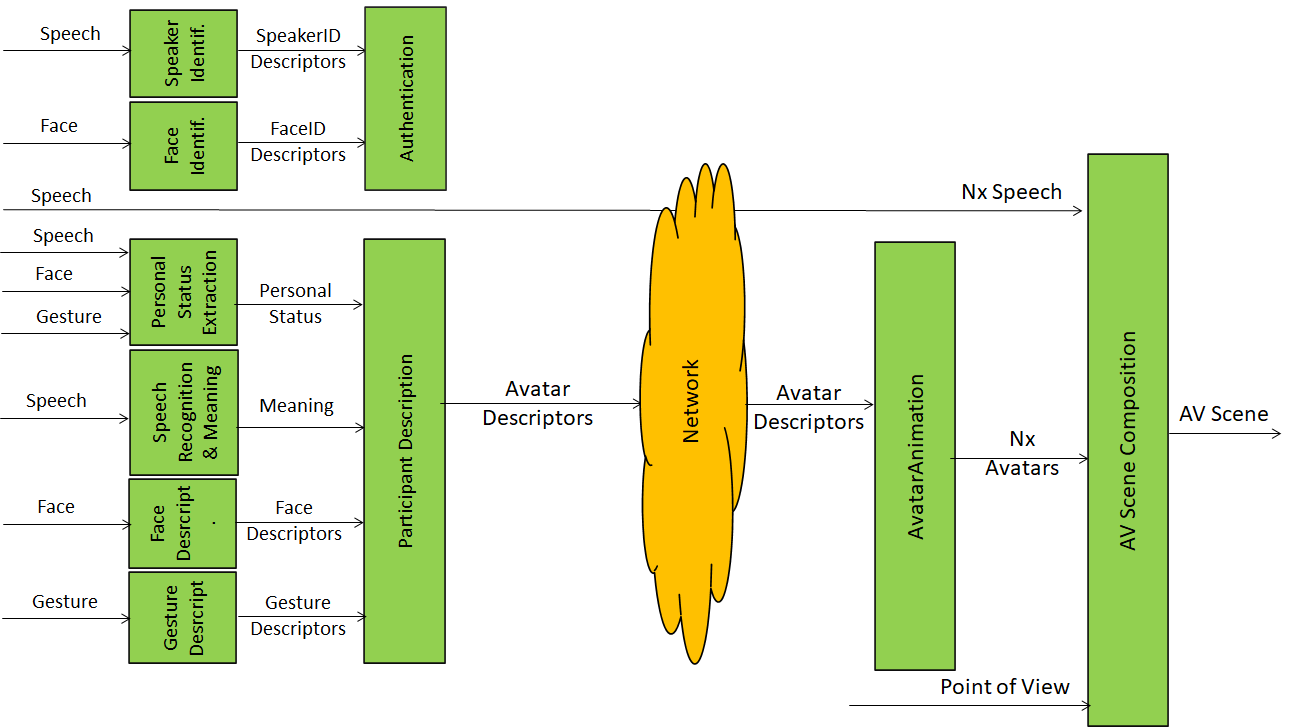
Figure 3 – The avatar-based videoconference use case
This is the sequence of operations:
- The Speaker Identification and Face Identification modules produce Speech and Face Descriptors that the Authentication module in the server uses to identify the participant.
- The Personal Status Extraction module produces the Personal Status.
- The Speech Recognition and Meaning produces the Meaning.
- The Face Description and Gesture Description modules produce the Face and Gesture Descriptors (for feature and motion).
- The Participant Description module uses Personal Status, Meaning, and Face and Gesture Descriptors to produce the Avatar Descriptors.
- The Avatar Animation module animates the individual participant’s Avatar Model using the Avatar Descriptors.
- The AV Scene Composition module places the participants’ avatars in their assigned places, attaches to each avatar its own speech and produces the Audio-Visual Scene that the participant can view and navigate.
The MPAI-MMC V2 use cases require the following technologies
- Audio Scene Description.
- Visual Scene Description.
- Speech Descriptors for:
- Speaker identification.
- Personal status extraction.
- Human Object Descriptors.
- Face Descriptors for:
- Face identification.
- Personal status extraction.
- Feature extraction (e.g., for avatar model)
- Motion extraction (e.g., to animate an avatar).
- Gesture Descriptors for:
- Personal Status extraction.
- Features (e.g., for avatar model)
- Motion (e.g., to animate an avatar).
- Personal Status.
- Avatar Model.
- Environment Model.
- Human’s virtual twin animation.
- Animated avatar manifesting a machine producing text and personal status.
The MPAI-MMC V2 standard is an opportunity for the industry to agree on a set of data formats so a market of modules can be created that is able to handle those formats. The standard should be extensible, in the sense that as new more performing technologies mature, they can be incorporated into the standard.
Please see:
- The 2 min video (YouTube and non-YouTube) illustrating MPAI-MMC V2.
- The slides presented at the online meeting on 2022/07/12.
- The Video recording of the online presentation (Youtube,non-YouTube) made at that 12 July presentation.
- The Call for Technologies, Use Cases and Functional Requirements, Framework Licence. and Template for responses.


