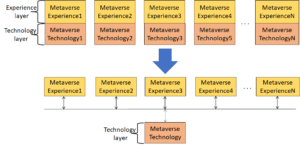
Autonomous User (A-User) is an autonomous agent able to move and interact (converse, etc.) with another User in a metaverse. It is a “conversation partner in a metaverse interaction” with the User, itself an A-User or and H-User directly controlled by a human. The figure shows a diagram of the A-User while the User generates audio-visual streams of information and possibly text as well.
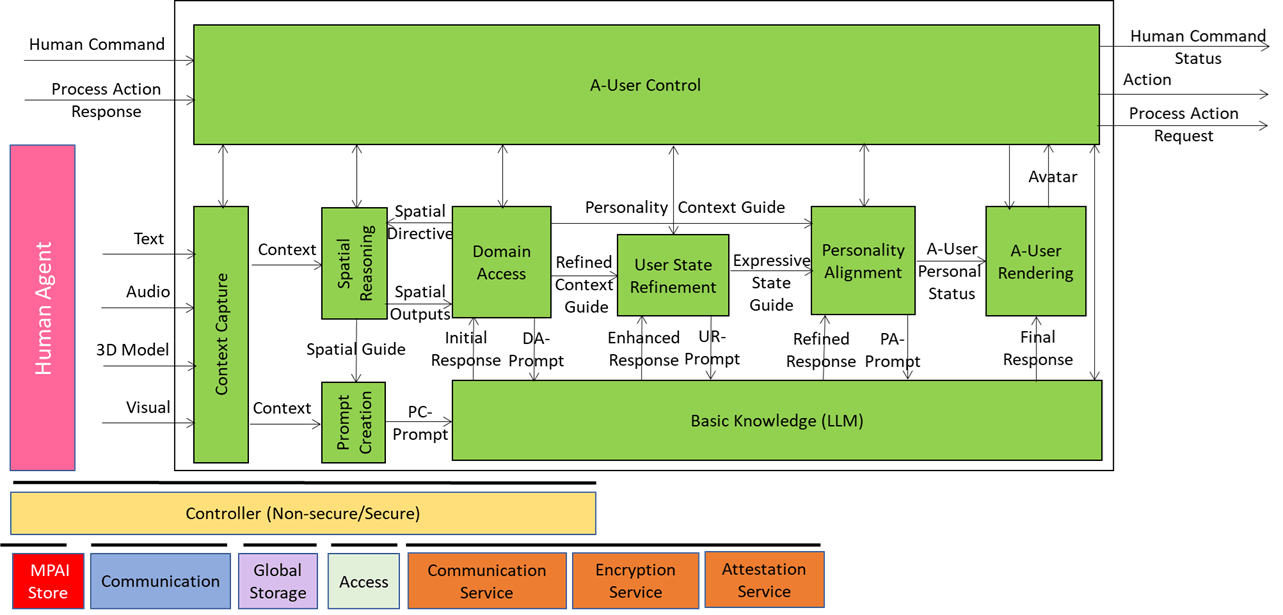
We have already presented the system diagram of the Autonomous User (A-User), an autonomous agent able to move and interact (walk, converse, do things, etc.) with another User in a metaverse. The latter User may be an A-User or be under the direct control of a human and is thus called a Human-User (H-User). The A-User acts as a “conversation partner in a metaverse interaction” with the User.
This is the third of a sequence of aiming at illustrating more in depth the architecture of an A-User and provide an easy entry point for those who wish to respond to the MPAI Call for Technology on Autonomous User Architecture. The first two dealt with the Control performed by the A-User Control AI Module on the other components of the A-User and how the A-User captures the external metaverse environment using the Context Capture AI Module.
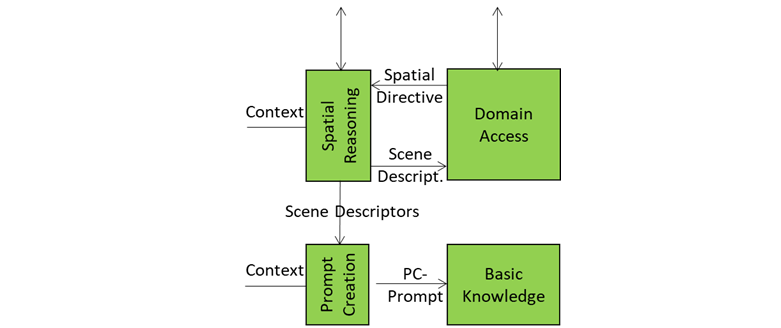
Audio Spatial Reasoning is the A-User’s acoustic intelligence module – the one that listens, localises, and interprets sound not just as data, but as data having a spatially anchored meaning. Therefore, Its role is not just about “hearing”, it is also about “understanding” where sound is coming from, how relevant it is, and what it implies in the context of the User’s intent in the environment.
When the A-User system receives a Context snapshot from Context Capture – including audio streams with a position and orientation and a description of the User’s emotional state (called User State) – Audio Spatial Reasoning start an analysis of directionality, proximity, and semantic importance of incoming sounds. The conclusion is something like “That voice is coming from the left, with a tone of urgence, and its orientation is directed at the A-User.”
All this is represented with an extension of the Audio Scene Descriptors describing:
- Which audio sources are relevant
- Where they are located in 3D space
- How close or far they are
- Whether they’re foreground (e.g., a question) or background (e.g., ambient chatter)
This guide is sent to Prompt Creation and Domain Access. Let’s see what happens with the former. The extended Audio Scene Descriptors are fused with the User’s spoken or written input and the current User State. The result is a PC-Prompt – a rich query enriched with text expressing the multimodal information collected so far – that is passed to Basic Knowledge for reasoning.
The Audio Scene Descriptors are further processed and integrated with domain-specific information. The response is called Audio Spatial Directive that includes domain-specific logic, scene priors, and task constraints. For example, if the scene is a medical simulation, Domain Access might tell Audio Spatial Reasoning that “only sounds from authorised personnel should be considered”. This feedback helps Audio Spatial Reasoning refine its interpretation – filtering out irrelevant sounds, boosting priority for critical ones, and aligning its spatial model with the current domain expectations.
Therefore, we can call Audio Spatial Reasoning as the A-User’s auditory guide. It knows where sounds are coming from, what they mean, and how they should influence the A-User’s behaviour. The A-User responds to a sound with spatial awareness, contextual sensitivity, and domain consistency.
There are still about two mounts to the deadline of 2025/01/19 when responses Call must reach the MPAI Secretariat (secretariat@mpai.community) without exception.
To know more, register to attend the online presentations of the Call on 17 November at 9 UTC (https://tinyurl.com/y4antb8a) and 16 UTC (https://tinyurl.com/yc6wehdv) – Today or tomorrow depending on where you are.