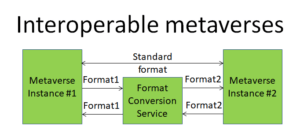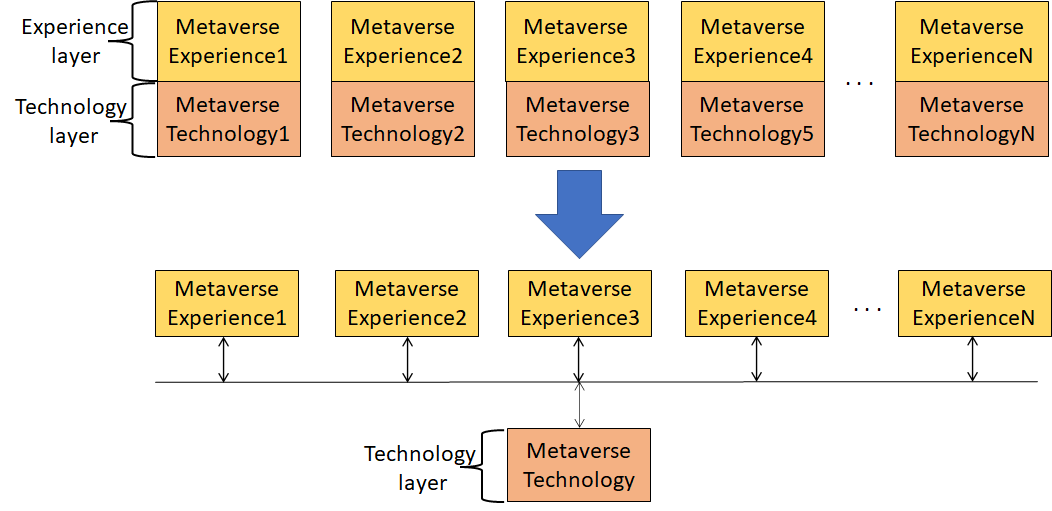
Purpose of this paper is to show that the figure is not just a wishful vision because concrete steps are being made to make the figure an actionable vision.
The question to ask now is: what technologies should be contained in the Metaverse Technology layer?
The top-down approach is certainly attractive. We can start conceiving Metaverse experiences and then list all technologies needed to support them.
While this approach may be thorough, it would be very long. Instead we can leverage the work that is being done within MPAI and draw from the technologies that are being standardised there.
MPAI has developed 2 standards that include several use cases. Here are the use cases relevant for the Metaverse and the technologies standardised by each of them.
CAE-EES – Emotion Enhanced Speech
A Speech Object without any embedded emotion is changed by embedding in it an emotion that is either of a standard list of emotions or by imitating the emotion embedded in a model Speech Object.
Technologies:
- Extraction of Speech Features from a Speech Object.
- Creation of Emotional Speech Features
- Injection of Speech Features into a Speech Object.
- Standard emotions classification.
MMC-UST – Unidirectional Speech Translations
A Speech Object composed of speech in a given language with any emotion or colour is automatically translated into another language preserving the original emotion or colour.
Technologies:
- Extraction of Text from a Speech Object.
- Conversion of Text from one language to another.
- Conversion of Text to a Speech Object.
- Extraction of Speech Features from a Speech Object.
- Injection of Speech Features into a Speech Object.
CAE-EAE – Enhanced Audioconference Experience
The Audio Object of an audio/videoconference room captured by a microphone array is processed to separate its Speech Objects from the other Audio Objects, separate the individual Speech Objects and create a description of the Audio Space. The processing yields an Audio Object containing the Audio Space description and the separated Speech Objects for transmission to a Metaverse.
Technologies:
- Spatial locations of the Sound Objects in a composite Sound Object.
- Separation of Speech Objects from a composite Sound Object.
- Cancellation of noise from a Speech Object.
- Audio Scene Geometry.
MMC-CWE – Conversation with Emotion
A Text, a Speech Object and a Visual Object of the face of the speaker (text and speech are alternative) are processed to extract text, emotion and meaning embedded in them. The Metaverse processes the 3 inputs and produces text and text with emotion which are appropriate responses to the 3 inputs. Further, the Metaverse converts text with emotion to a Speech Object, and uses the latter Speech Object and the output emotion to animate the lips of an Avatar.
Technologies:
- Extraction of Text from a Speech Object.
- Extraction of Emotion from a Speech Object.
- Extraction of Emotion from a Text.
- Extraction of Facial Emotion from a Human Object
- Extraction of Meaning from a Text.
- Conversion of a Text with 1) Meaning, 2) Intention and 3) classified Emotion to a Text and a classified Emotion congruent with the original Text and classified Emotion.
- Conversion of a Text with a classified Emotion to a Speech Object with the classified Emotion embedded in it.
- Conversion of a Speech Object and a classified Emotion to a face of Virtual Visual Human expressing the classified Emotion and whose lips move synchronously with the Speech Object.
MMC-MQA – Multimodal Question Answering
A Speech Object and a Visual Object of a speaker holding an object are processed to extract text, meaning and intention embedded in them. The the 3 inputs are processed and a Speech Object which are appropriate responses to the 2 inputs is produced.
Technologies:
- Extraction of Text from a Speech Object.
- Identification of a Generic Object held by a Human Object
- Extraction of Meaning from the combination of Text and object identifier.
- Extraction of Intention from Meaning.
- Conversion of a Text, Intention and Meaning to a response Text that is congruent with the input.
- Conversion of a Text to a Speech Object.
It is interesting to note that, quite a few of the technologies are re-used by different use cases. This is a consequence of the component-based approach of MPAI standards.
Clearly, the current list of technologies is short and insufficient to build a metaverse technology layer. But the technologies listed are only the result of the first 15 months of MPAI work and more technologies are being prepared based on the 2022 work program.
In a future post I will describe some of the planned new technologies.