The third context of the Context-based Audio Enhancement (MPAI-CAE) standard is restoration of damaged speech.
Unlike Audio Recording Preservation where audio has clear provenance – the magnetic tape of an open reel whose analogue audio has been digitised – Speech Restoration System does not make a reference to anything analogue. It assumes that there is a file containing digital speech. For whatever reason, it may be so that portions of the file are damaged – maybe the physical medium from which the file was created was partly corrupted. However, the use case assumes that the text that the creator used to make their speech is available.
Figure 1 shows the AI Modules (AIM), i.e., the components of the system
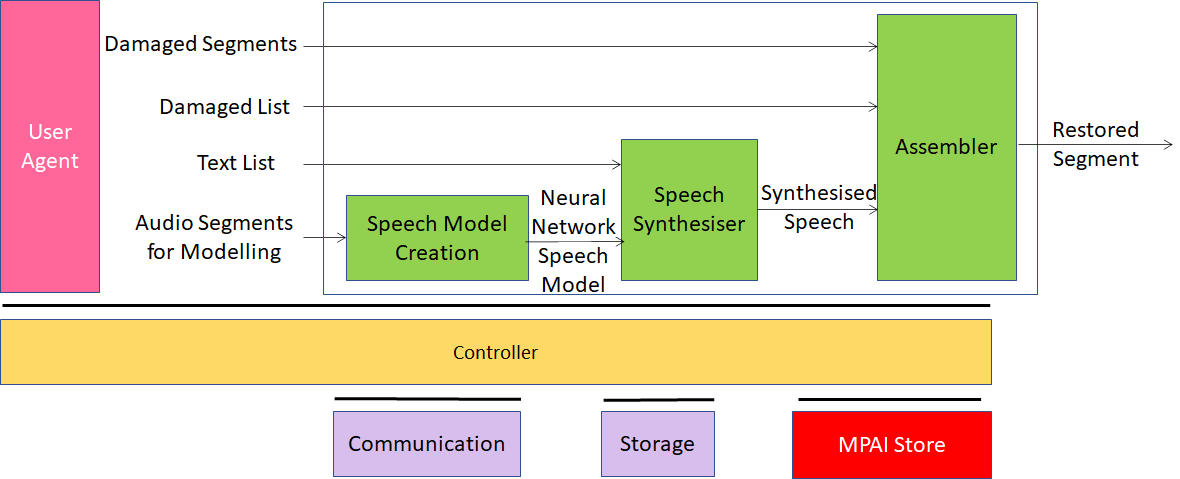
Figure 1 – The Speech Restoration System Reference Model
The basic idea is to create a speech model using a sufficient number of undamaged audio segments. The model is then served to a neural network acting as a speech synthesiser of the original that is used to synthesise all damaged speech segments in the list of damaged speech segments using the text corresponding to the damaged segment.
The result is an entirely restored speech file where the damaged segments have been replaced by the best estimate of the speech produced by the speaker.
It is time to become an MPAI member https://mpai.community/how-to-join/join/. Join the fun – build the future!