Autonomous User (A-User) is an autonomous agent able to move and interact (converse, etc.) with another User in a metaverse. It is a “conversation partner in a metaverse interaction” with the User, itself an A-User or an H-User directly controlled by a human. The figure shows a diagram of the A-User while the User generates audio-visual streams of information and possibly text as well.
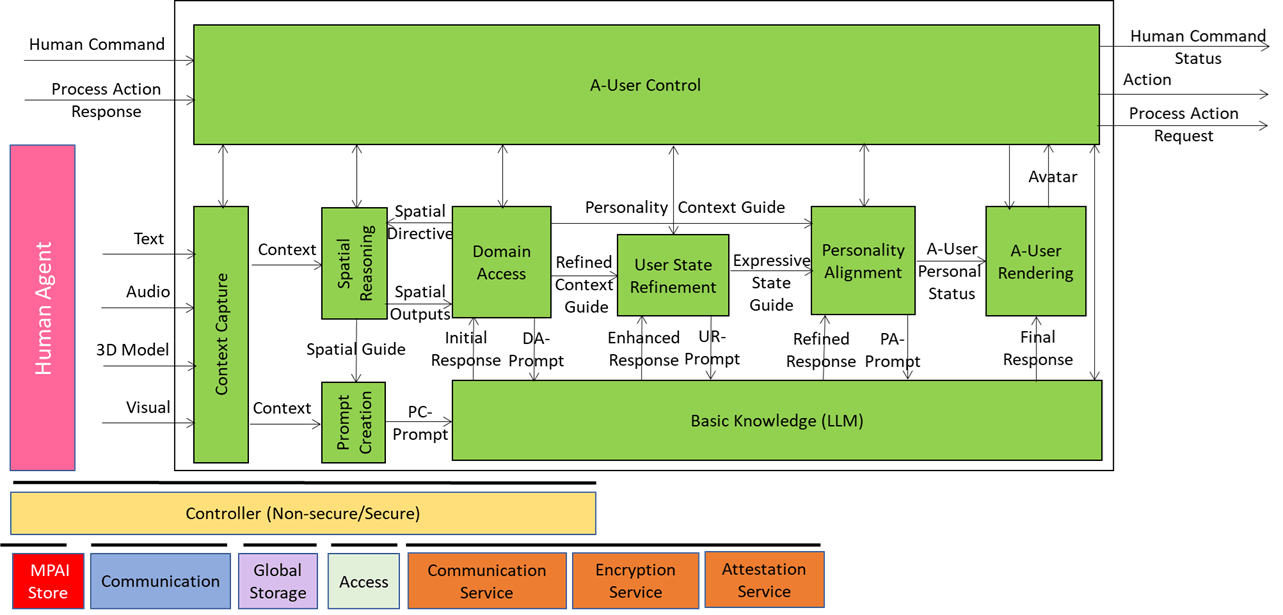
This is the fourth of a sequence of posts aiming to illustrate the architecture of an A-User and provide an easy entry point for those who wish to respond to the MPAI Call for Technology on Autonomous User Architecture. The first three dealt with 1) the Control performed by the A-User Control AI Module on the other components of the A-User, 2) how the A-User captures the external metaverse environment using the Context Capture AI Module, and 3) listens, localises, and interprets sound not just as data, but as data having a meaning and a spatial anchor.
When the A-User acts in a metaverse space, sound doesn’t tell the whole story. The visual scene – objects, zones, gestures, occlusions – is the canvas where situational meaning unfolds. That’s where Visual Spatial Reasoning comes in: it’s the interpreter that makes sense of what the Autonomous User sees, not just what it hears.
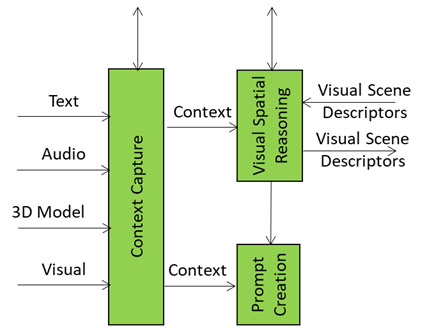
Visual Spatial Reasoning can be considered as the visual analyst embedded in the “brain” of the Autonomous User. It doesn’t just list objects; it understands their geometry, relationships, and salience. A chair isn’t just “a chair” – it’s occupied, near a table, partially occluded, or the focus of attention. By enriching raw descriptors into structured semantics, Visual Spatial Reasoning transforms objects made of pixels into actionable targets.
This is what it does
- Scene Structuring: Takes and organises raw visual descriptors into coherent spatial maps.
- Semantic Enrichment: Adds meaning – classifying objects, inferring affordances, and ranking salience.
- Directed Alignment: Filters and prioritises based on the A-User Controller’s intent, ensuring relevance.
- Traceability: Every refinement step is auditable, to trace back why, “that object in the corner” became “the salient target for interaction.”
Why It Matters
Without Visual Spatial Reasoning, the metaverse would be a flat stage of unprocessed visuals. With it, visual scenes become interpretable narratives. It’s the difference between “there are three objects in the room” and “the User is focused on the screen, while another entity gestures toward the door.”
Of course, Visual Spatial Reasoning does not replace vision. It bridges the gap between raw descriptors and effective interaction, ensuring that the A‑User can observe, interpret, and act with precision and intent.
If Audio Spatial Reasoning is the metaverse’s “sound‑aware interpreter,” then Visual Spatial Reasoning is its “sight‑aware analyst” that starts by seeing objects and eventually can understand their role, their relevance, and their story in the scene.