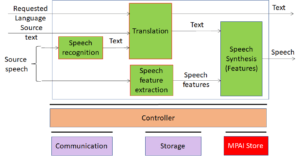
On the 30th of September 2021, on the first anniversary of its incorporation, MPAI approved Version 1 of its Multimodal Conversation standard (MPAI-MMC). The standard included 5 use cases: Conversation with Emotion, Multimodal Question Answering and e Automatic Speech Translation Use Cases. Three months later, MPAI approved Version 1 of Context-based Audio Enhancement (MPAI-CAE). The standard included 4 use cases: Emotion-Enhanced Speech, Audio Recording Preservation, Speech Restoration System and Enhanced Audioconference Experience.
A lot more has happened in MPAI beyond these two standards, even before the approval of the two standards, and now MPAI is ready to launch a new project that includes 5 use cases:
- Personal Status Extraction (PSE).
- Personal Status-driven Avatar (PSA).
- Conversation About a Scene (CAS).
- Human-CAV (Connected Autonomous Vehicle) Interaction (HCI).
- Avatar-Based Videoconference (ABV).
This article will give a brief introduction to the 5 use cases.
- Personal Status Extraction (PSE). Personal Status is a set of internal characteristics of a person, currently, Emotion, Cognitive State, and Attitude. Emotion and Cognitive State result from the interaction of a human with the Environment. Cognitive State is more rational (e.g., “Confused”, “Dubious”, “Convinced”). Emotion is less rational (e.g., “Angry”, “Sad”, “Determined”). Attitude is the stance that a human takes when s/he has reached an Emotion and Cognitive State (e.g., “Confrontational”, “Respectful”, “Soothing”). The PSE use case is about how Personal Status can be extracted from its Manifestations: Text, Speech, Face and Gesture.
- Personal Status-driven Avatar (PSA). In Conversation with Emotion (MPAI-MMC V1) a machine was represented by an avatar whose speech and face displayed an emotion congruent with the emotion displayed by a human the machine is conversing with. The PSA use case is about the interaction of a machine with humans in different use cases. The machine is represented by an avatar whose text, speech, face, and gesture display a Personal Status congruent with the Personal Status manifested by the human the machine is conversing with.
- Conversation About a Scene (CAS): A human and a machine converse about the objects in a room with little or no noise. The human uses a finger to indicate their interest in a particular object. The machine understands the Personal Status shown by the human in their speech, face, and gesture, e.g., the human’s satisfaction because the machine understands their question. The machine manifests itself as the head-and-shoulders of an avatar whose face and gesture (head) convey the machine’s Personal Status resulting from the conversation in a way that is congruent with the speech it utters.
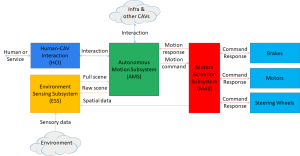
- Human-CAV (Connected Autonomous Vehicle) Interaction (HCI): a group of humans converse with a Connected Autonomous Vehicle (CAV) on a domain-specific subject (travel by car). The conversation can be held both outside of the CAV when the CAV recognises the humans to let them into the CAV or inside when the humans are sitting in the cabin. The two Environments are assumed to be noisy. The machine understands the Speech, and the human’s Personal Status shown on their Text, Speech, Face, and Gesture. The machine appears as the head and shoulders of an avatar whose Text, Speech, Face, and Gesture (Head) convey a Personal Status congruent with the Speech it utters.
- Avatar-Based Videoconference (ABV). Avatars representing geographically distributed humans participate in a videoconference reproducing the movements of the upper part of the human participants (from the waist up) with a high degree of accuracy. Some locations may have more than one participant. A special participant in the Virtual Environment where the Videoconference is held can be the Virtual Secretary. This is an entity displayed as an avatar not representing a human participant whose role is to: 1) make and visually share a summary of what other avatars say; 2) receive comments on the summary; 3) process the vocal and textual comments taking into account the avatars’ Personal Status showing in their text, speech, face, and gesture; 4) edit the summary accordingly; and 5) display the summary. A human participant or the meeting manager composes the avatars’ meeting room and assigns each avatar’s position and speech as they see fit.
These use cases imply a wide range of technologies (more than 40). While the requirements for these technologies and the full description of the use cases are planned to be approved at the next General Assembly (22 June), MPAI is preparing the Framework Licence and the Call for Technologies. The latter two are planned to be approved at the next-to-next General Assembly on 19 July. MPAI gives respondents about 3 months to complete their submissions.
More information about the MPAI process and the Framework Licence is available on the MPAI website.