As reported in a previous post, MPAI is busy finalising the “Use Cases and Functional Requirements” document of MPAI-MMC V2. One use case is Avatar-Based Videoconference (ABV), part of the Mixed-reality Collaborative Space (MCS) project supporting scenarios where geographically separated humans represented by avatars collaborate in virtual-reality spaces.
ABV refers to a virtual videoconference room equipped with a table and an appropriate number of chairs to be occupied by:
- Speaking virtual twins representing human participants displayed as the upper part of avatars resembling their real twins.
- Speaking human-like avatars not representing humans, e.g., a secretary taking notes of the meeting, answering questions, etc.
In line with the MPAI approach to standardisation, this article will report the currently defined functions, input/output data, AIM topology of the AI Workflow (AIW) of the Virtual Secretary, and the AI Modules (AIM) and their input/output data. The information in this article is expected to change when it will be published as an annex to the upcoming Call for Technologies.
The functions of the Virtual Secretary are:
- To collect and summarise the statements made by participating avatars.
- To display the summary for participants to see, read and comment on.
- To receive sentences/questions about its summary via Speech and Text.
- To monitor the avatars’ emotions in their speech and face, and expression in their gesture.
- To change the summary based on avatars’ text from speech, emotion from speech and face, and expression from gesture.
- To respond via speech and text, and display emotion in text, speech, and face.
The Virtual Secretary workflow in the AI Framework is depicted in Figure 1.
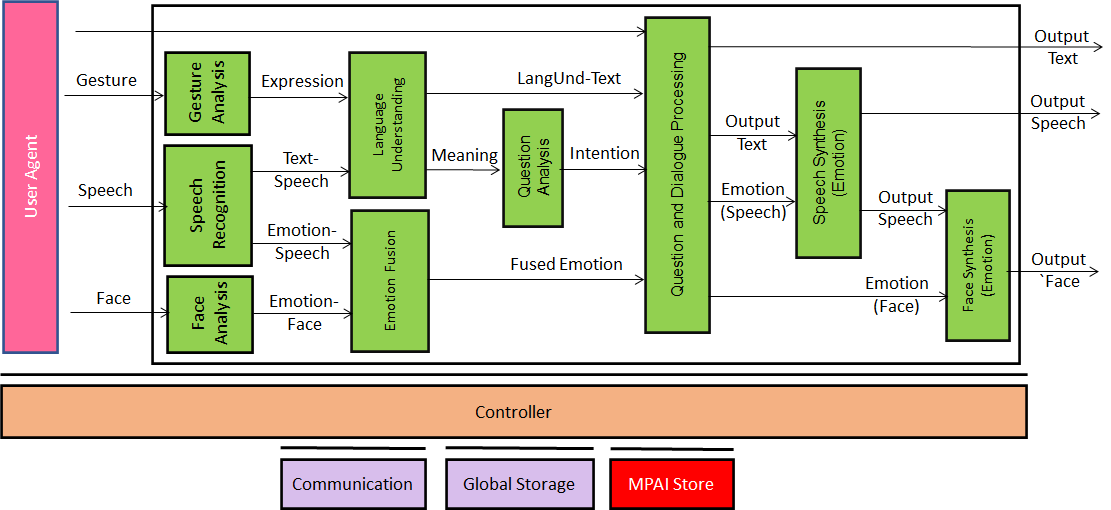
Figure 1 – Reference Model of Virtual Secretary
The operation of the workflow can be described as follows:
- The Virtual Secretary recognises the speech of the avatars.
- The Speech Recognition and Face Analysis extract the emotions from the avatars’ speech and face.
- Emotion Fusion provides a single emotion based on the two emotions.
- Gesture Analysis extracts the gesture expression.
- Language Understanding uses the recognised text and the emotion in speech to provide the final version of the input text (LangUnd-Text) and the meaning of the sentence uttered by an avatar.
- Question analysis uses the meaning to extract the intention of the sentence uttered by an avatar.
- Question and Dialogue Processing (QDP) receives LangUnd-Text and the text provided by a participant via chat and generates:
- The text to be used in the summary or to interact with other avatars.
- The emotion contained in the speech to be synthesised.
- The emotion to be displayed by the Virtual Secretary avatar’s face.
- The expression to be displayed by the Virtual Secretary’s avatar
- Speech Synthesis (Emotion) uses QDP’s text and emotion and generates the Virtual Secretary’s synthetic speech with the appropriate embedded emotion.
- Face Synthesis (Emotion) uses the avatar’s synthetic speech and QDP’s face emotion to animate the face of the Virtual Secretary’s avatar.
The data types processed by the Virtual Secretary are:
Avatar Descriptors allow the animation of an Avatar Model based on the description of the movement of:
- Muscles of the face (e.g., eyes, lips).
- Head, arms, hands, and fingers.
Avatar Model allows the use of avatar descriptors related to the model without the lower part (from the waist down) to:
- Express one of the MPAI standardised emotions on the face of the avatar.
- Animate the lips of an avatar in a way that is congruent with the speech it utters, its associated emotion and the emotion it expresses on the face.
- Animate head, arms, hands, and fingers to express one of the Gestures to be standardised by MPAI, e.g., to indicate a particular person or object or the movements required by a sign language.
- Rotate the upper part of the avatar’s body, e.g., as need if the avatar turns to watch the avatar next to itself.
Emotion of a Face is represented by the MPAI standardised basic set of 59 static emotions and their semantics. To support the Virtual Secretary use case, MPAI needs new technology to represent a sequence of emotions each having a duration and a transition time. The dynamic emotion representation should allow for two different emotions to happen at the same time, possibly with different durations.
Face Descriptors allow the animation of a face expressing emotion, including at least eyes (to gaze at a particular avatar) and lips (animated in sync with the speech).
Intention is the result of analysis of the goal of an input question standardised in MPAI-MMC V1.
Meaning is information extracted from an input text and physical gesture expression such as question, statement, exclamation, expression of doubt, request, invitation.
Physical Gesture Descriptors represent the movement of head, arms, hands, and fingers suit-able for:
- Recognition of sign language.
- Recognition of coded hand signs, e.g., to indicate a particular object in a scene.
- Representation of arbitrary head, arm, hand, and finger motion.
- Culture-dependent signs (e.g, mudra sign).
Spatial coordinates allow the representation of the position of an avatar, so that another avatar can gaze at its face when it has a conversation with it.
Speech Features allow a user to select a Virtual Secretary with a particular speech model.
Visual Scene Descriptors allow the representation of a visual scene in a virtual environment.
In July MPAI plans on publishing a Call for Technologies for MPAI-MMC V2. The Call will have two attachments. The first is the already referenced Use Cases and Functional Requirements document, the second is the Framework Licence that those responding to the Call shall accept in order to have their response considered.