
It will take some time before we can have a casual conversation with a machine, but there is significant push by the industry to endow machines with the ability to hold even limited forms of conversation with humans.
The MPAI-MMC standard, approved on 30th of September provides two significant examples.
The first is Conversation with Emotion (MMC-CWE) depicted in Figure 1. it assumes there is a machine that responds to user queries. The query can be about the line of products sold by a company or by the operation of a product or complaints about a malfunctioning product.
It would be a great improvement over some systems available today if the machine could understand the state of mind of the human and fine-tune its speech so as to make it more in tune with the mood of the human.
MPAI-CWE standardises the architecture of the processing units (called AIM Modules – AIMs) and the data formats exchanged by the processing units that support the following scenario: a human types or speaks to a machine that captures the human’s text or speech and face, and responds with a speaking avatar.
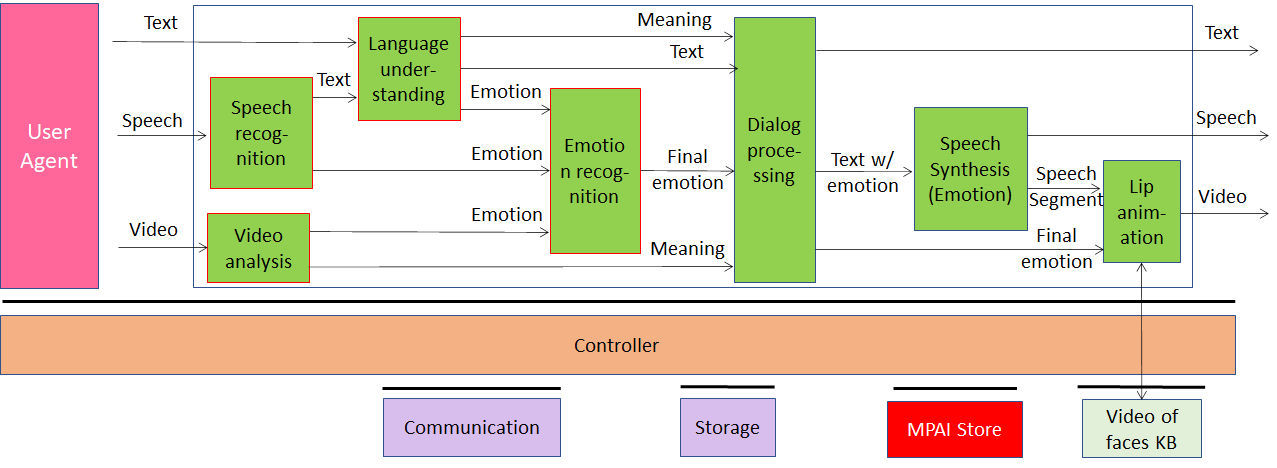
Figure 1 – Conversation with Emotion
A Video Analysis AIM extracts emotion and meaning from the human’s face and the the Speech Recognition AIM converts the speech to text and extracts emotion from the human’s speech. Emotion from different media is fused and all the data are passed to Dialogue Processing AIM that provides the machine’s answer along with the appropriate emotion. Both are passed to a speech synthesiser AIM and a lips animation AIM.
The second case is Multimodal Question Answering (MMC-MQA) depicted in Figure 2. Here MPAI has done the same for a system where a human handles an object in their hand and asks a question about the object that the machine answers with synthetic voice.
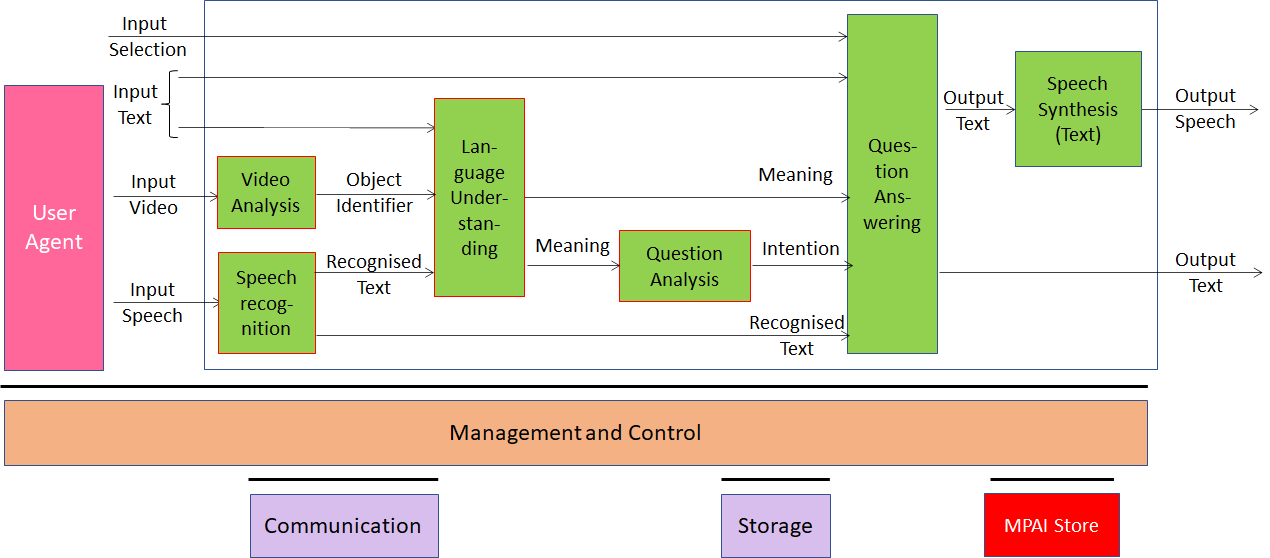
Figure 2 – Multimodal Question Answering
An AIM recognises the object while a speech recogniser AIM converts the speech of the human to text. The text with information about the object is processed by the Language Understanding AIM that produces Meaning which Question Analysis AIM converts to Intention. The Question Answering AIM processes human text, intention and meaning to produce the machine’s answer that is finally converted into synthetic speech.
MPAI is now exploring other environments where human-machine conversation is possible with technologies within reach.
The third case is Human to Connected Autonomous Vehicle (CAV) Interaction depicted in Figure 3. In this case the CAV should be able to
- Recognise that the human has indeed the right to ask the CAV to do anything to the human.
- Understand commands like “take me home” and respond by offering a range of possibilities among which the human can choose.
- Respond to other questions while travelling and engage in a conversation with the human.
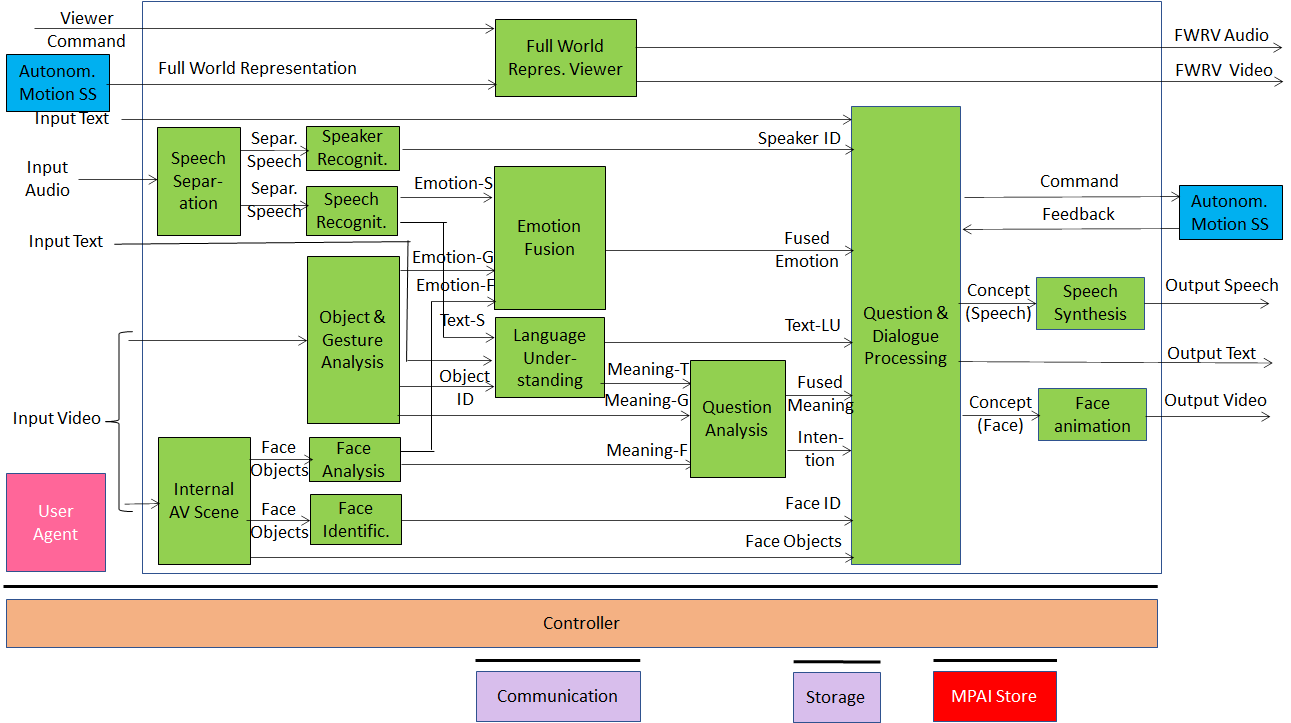
Figure 3 – Human to Connected Autonomous Vehicle dialogue
The CAV is impersonated by an avatar which is capable to do several additional things compared to the MMC-CWE case such as distinguish which human in the compartment is asking a question and turn its eyes to that human.
The fourth case Conversation About a Scene, depicted in Figure 4 is actually an extension of Multimodal Question Answering: a human and a machine are holding a conversation on the objects of a scene. The machine understands what the human is saying and the object they are pointing to, by looking at the changes in the face and in the speech denoting approval or disapproval etc.
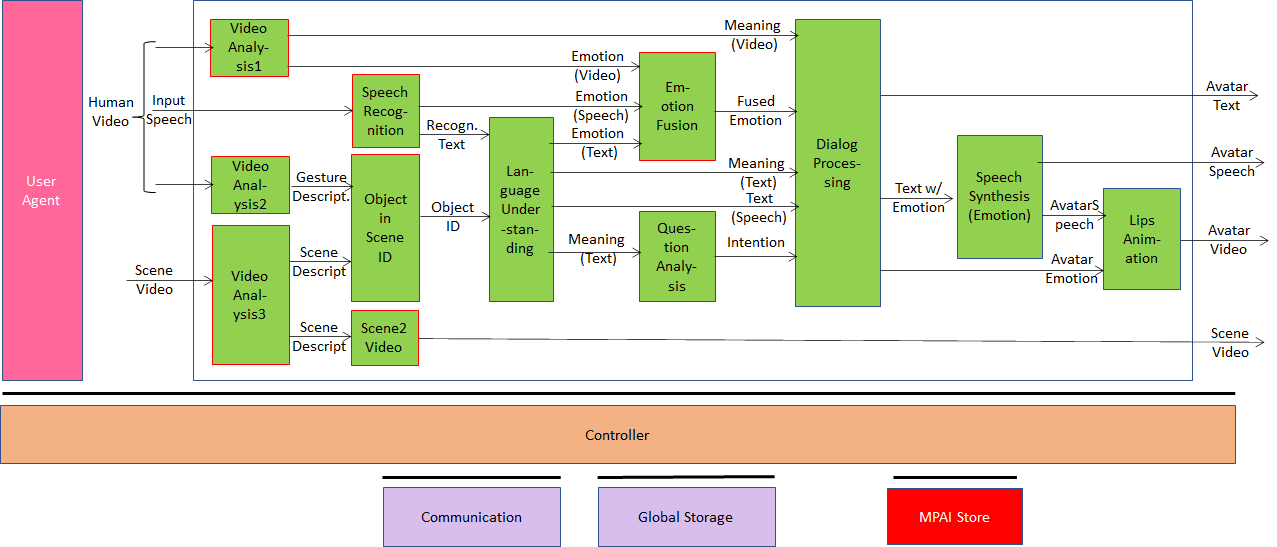
Figure 4 – Conversation About a Scene
Figure 4 represents the architecture of the AIMs whose concurrent actions allow a human and a machine to have a dialogue. It integrates the emotion-detecting AIMs of MMC-CWE and the question-handling AIMs of MMC-MQA with the AIM that detects the human gesture (“what the human arm/finger is pointing at”) and the AIM that created a model of the objects in the scene. The Object in Scene AIM fuses the two data and provides the object identifier that is processed in a way similar to MMC-MQA.
The fifth case is part of a recent new MPAI project called Mixed-reality Collaborative Spaces (MPAI-MCS) depicted in Figure 5, applicable to scenarios where geographically separated humans collaborate in real time with speaking avatars in virtual-reality spaces called ambient to achieve goals generally defined by the use scenario and specifically carried out by humans and avatars.
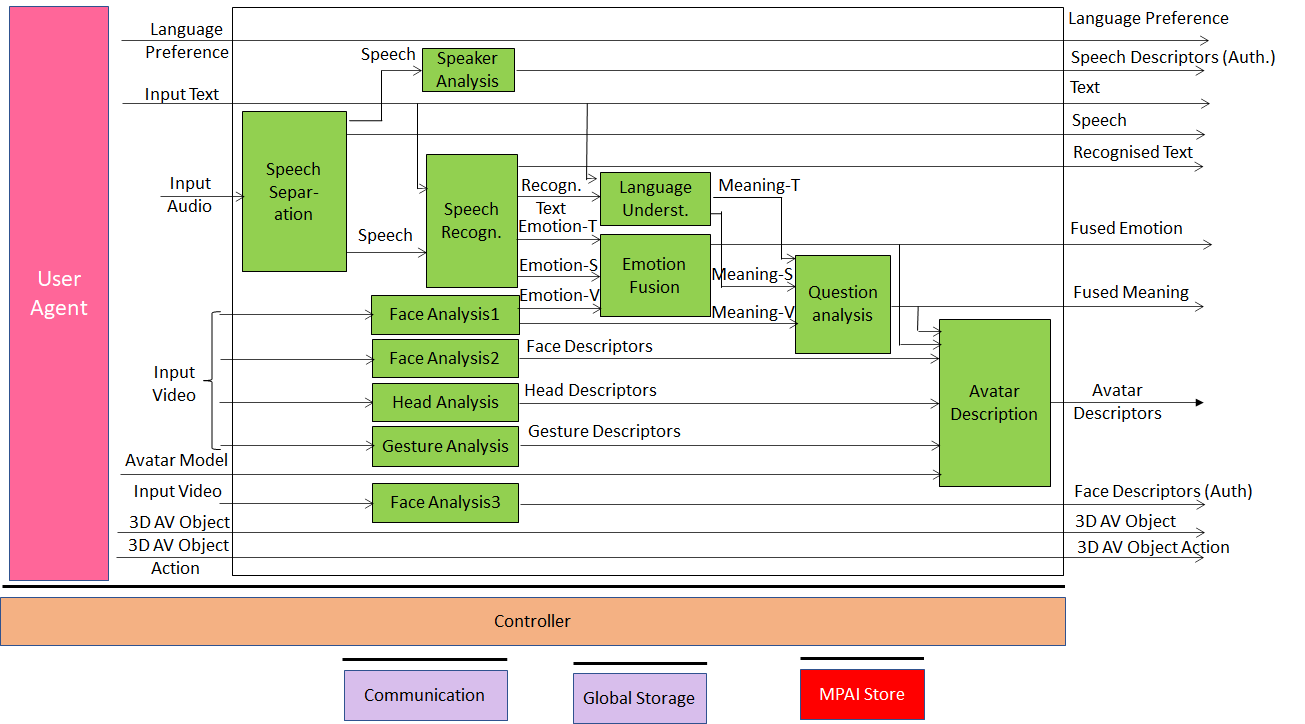
Figure 5 – Mixed-reality Colleborative Space.
Strictly speaking, in MCS the problem is not conversation with a machine but creation of a virtual twin of a human (an avatar) looking like and behaving in a similar way as its physical twin. Many AIMs we need for this case are similar to and in some cases exactly the same as those needed by MMC-CWE and MMC-MQA: we need to capture the emotion or the meaning on the face and in the speech and in the physical twin so that we can map them to the virtual twin.
