
Today video/audio conference is a virtual space where many of us spend their working hours. Still the experience of a conference suffer from many deficiencies depending on the fact that the way audio is captured and conveyed to the virtual space is inadequate. Our brains can separate the voice of competing speakers, and remove the effect of non-ideal acoustical properties of the physical space and/or the background noise in the same in the same physical environment.
However, when the acoustic signals from the different physical environments are merged in the virtual space, the operation of our brains can well not be as efficient. The result is a reduction in intelligibility of speech causing participants not fully understanding what their interlocutors are saying. The very purpose of the conference may be harmed and, at the end of the day, participants may very well feel more stressed than when they could meet people in person.
Many of these problems can be alleviated or resolved if a microphone array is used to capture the speakers’ speech signals. The individual speech signals can be separated, the non-ideal acoustics of the space can be reduced and any background noise can be substantially suppressed.
The fourth context of Context-based Audio Enhancement (MPAI-CAE), called Enhanced Audioconference Experience (CAE-EAE), aims to provide a complete solution enabling the processing of speech signals from a microphone array to provide clear speech signals free from background noise and acoustics-related artefacts to improve the auditory quality of an audioconference experience. Specifically, CAE-EAE addresses the situation where one or more speakers are active in a noisy meeting room and try to communicate using speech with one or more interlocutors over the network.
The AIM Modules (AIM) required by this use case extract the speech signals of the individual speakers from the microphone array and reduce background noise and reverberation. CAE-EAE can also extract the spatial attributes of the speakers with respect to the position of the microphone array. This information, multiplexed with the multichannel audio can be properly used at the receiver side to create a spatial representation of the speech signals.
Figure 1 depicts the AI Module structure whose operation is described below.
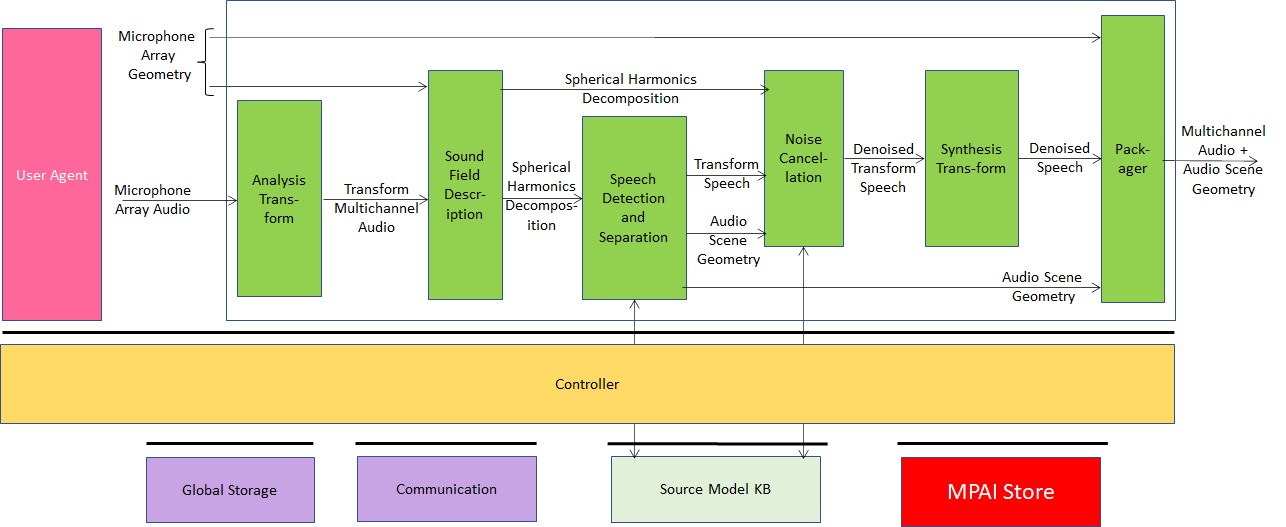
Figure 1 – Enhanced Audioconference Experience Reference Model
- Analysis Transform AIM performs a time-frequency transformation to enable the operations downstream to be carried out in the frequency domain.
- Sound Field Description AIM converts the output from the Analysis Transform AIM into the spherical frequency domain.
- Speech Detection and Separation AIM detects the directions of active sound sources and separates the sources using the Source Model KB which provides simple acoustic source models. The separated sources can either be speech or non-speech.
- Noise Cancellation AIM eliminates background noise and reverberation producing a Denoised Speech in the frequency domain.
- Synthesis Transform AIM applies the inverse transform to Denoised Speech.
- Packager AIM produces a multiplexed stream which contains separated Multichannel Speech Streams and Audio Scene Geometry.
The MPAI CAE-EAE standard can change the experience of audio/video teleconference users.

