
Processing and generation of natural language is an area where artificial Intelligence is expected to make a difference compared to traditional technologies. Version 1 of the MPAI Multimodal Conversation standard (MPAI-MMC V1), specifically the Conversation with Emotion use case, has addressed this and related challenges: processing and generation not only of speech but also of the corresponding human face when both convey emotion.
The audio and video produced by a human conversing with the machine represented by the blue box in Figure 1 is perceived by the machine which then generates a human-like speech and video in response.
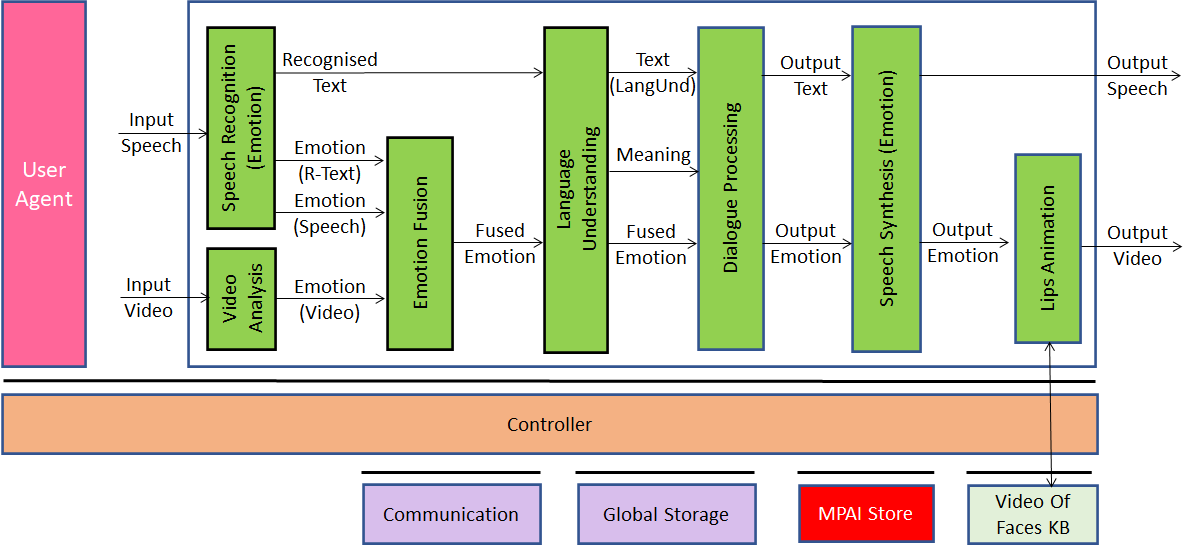
Figure 1 – Multimodal conversation in MPAI-MMC V1
The system depicted in Figure 1 operates as follows (bold indicates module, underline indicates output, italic indicates input):
- Speech Recognition (Emotion) produces Recognised Text from Input Speech and the Emotion embedded in Recognised Text and in Input Speech.
- Video Analysis extracts the Emotion expressed in Input Video (human’s face).
- Emotion Fusion fuses the three Emotions into one (Fused Emotion).
- Language Understanding produces Text (Language Understanding) from Recognised Text and Fused Emotion.
- Dialogue Processing generates pertinent Output Text and Output Emotion using Text, Meaning, and Fused Emotion.
- Speech Synthesis (Emotion) synthesises Output Speech from Output Text.
- Lips Animation generates Output Video displaying the Output Emotion with lips animated by Output Speech using Output Speech, Output Emotion and a Video drawn from the Video of Faces Knowledge Base.
The MPAI-MMC V2 Call for Technologies issued in July 2022, seeks four major classes of technologies enabling a significant extension of the scope of its use cases:
- The internal status of a human from Emotion, defined as the typically non-rational internal status of a human resulting from their interaction with the Environment, such as “Angry”, “Sad”, “Determined” to two more internal statuses: Cognitive State, defined as the typically rational internal status of a human reflecting the way they understand the Environment, such as “Confused”, “Dubious”, “Convinced”, and Attitude, defined as the internal status of a human or avatar related to the way they intend to position themselves vis-à-vis the Environment, e.g., “Respectful”, “Confrontational”, “Soothing”. Personal Status is the combination of Emotion, Cognitive State and Attitude. These can be extracted not only from speech and face but from text and gesture (intended as the combination of the head, arms, hands and fingers) as well.
- The direction suggested by the Conversation with Emotion use case where the machine generates an Emotion pertinent to what it has heard (Input Speech) and seen (human face of Input Video) but also to what the machine is going to say (Output Text). Therefore, Personal Status is not just extracted from a human but can also be generated by a machine.
- Enabling solutions no longer targeted to a controlled environment but facing the challenges of the real world: to enable a machine to create the digital representation of an audio-visual scene composed of speaking humans in a real environment.
- Enabling one party to animate an avatar model using standard descriptors and model generated by another party.
More information about Personal Status and its applications in Personal Status Extraction and Personal Status Display can be found in Personal Status in human-machine conversation.
With these technologies MPAI-MMC V2 will support three new use cases:
- Conversation about a scene. A human has a conversation with a machine about the objects in a room. The human uses gestures to indicate the objects of their interest. The machine uses a personal status extraction module to better understand the internal status of the human and produces responses that include text and personal status. The machine manifests itself via a personal status display module (see more here).
- Human-Connected Autonomous Vehicle (CAV) Interaction. A group of humans interact with a CAV to get on board, request to be taken to a particular venue and have a conversation with the CAV while travelling. The CAV uses a personal status extraction module to better understand the personal status of the humans and produces responses that include Text and Personal Status. The CAV manifests itself via a personal status display module (again, see more here).
- Avatar-Based Videoconference. (Groups of) humans from different geographical locations participate in a virtual conference represented by avatars animated by descriptors produced by their clients using face and gesture descriptors supported by speech analysis and personal status extraction. The server performs speech translation and distributes avatar models and descriptors. Each participant places the individual avatars animated by their descriptors around a virtual table with their speech. A virtual secretary creates an editable summary recognising the speech and extracting the personal status of each avatar.
Figure 2 represents the reference diagram of Conversation about a Scene.
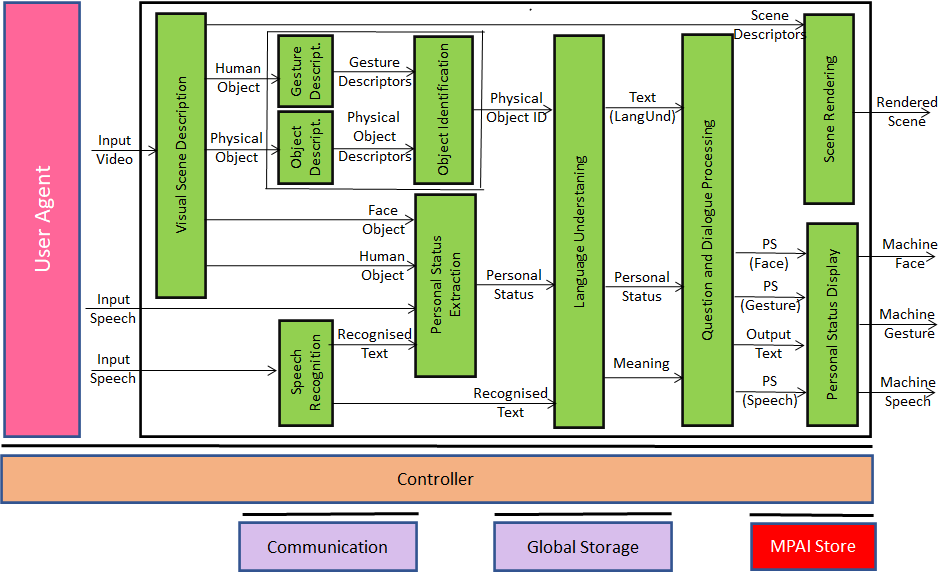
Figure 2 – Conversation about a Scene in MPAI-MMC V2
The system depicted in Figure 2 operates as follows:
- Visual Scene Description creates a digital representation of the visual scene.
- Speech Recognition recognises the text uttered by the human.
- Object Description, Gesture Description and Object Identification provide the ObjectID.
- Personal Status Extraction provides the human’s current Personal Status.
- Language Understanding provides Text (Language Understanding) and Meaning.
- Question and Dialogue Processing generates Output Text and the Personal State of each of Speech, Face and Gesture.
- Personal Status Display produces a speaking avatar animated by Output Text and the Personal State of each of Speech, Face and Gesture.
The internal architecture of the Personal Status Display module is depicted in Figure 3.
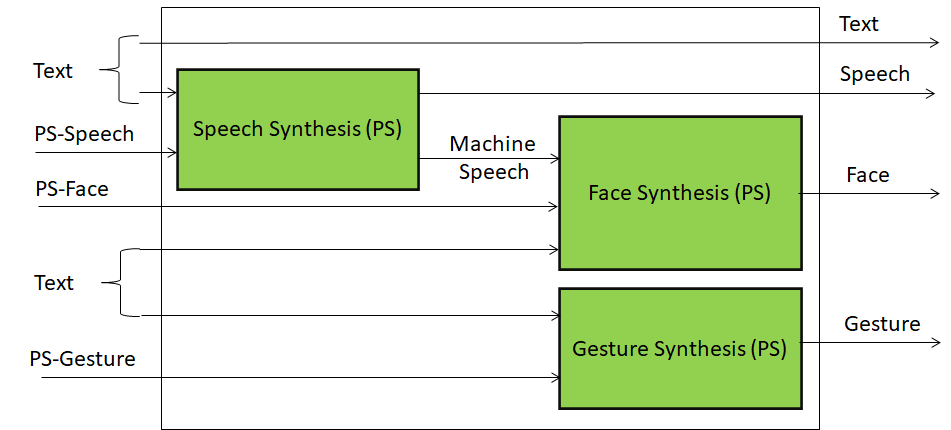
Figure 3 – Architecture of the Personal Status Display Module
Those wishing to know more about the MPAI-MMC V2 Call for Technologies should review:
- The 2′ video (YouTube, non-YouTube) illustrating MPAI-MMC V2.
- The slides presented at the online meeting on 2022/07/12.
- The video registration of the online presentation (YouTube, non-YouTube) made at that 12 July presentation.
- The Call for Technologies, Use Cases and Functional Requirements, Clarifications about MPAI-MMC V2 Call for Technologies data formats, Framework Licence, and Template for responses.
The MPAI Secretariat should receive the responses to the Call by 2022/10/10T23:59 UTC. Partial responses are welcome.