The goal of the Multimodal Conversation (MPAI-MMC) standard is to provide technologies that enable a human-machine conversation that is more human-like, richer in content, and able to emulate human-human conversation in completeness and intensity.
By learning from human interaction, machines can improve their “conversational” capabilities in the two main phases of conversation: understanding of the meaning of an element and the generation of a pertinent response.
Multimodal Conversation Version 2 achieves this goal by providing, among other technologies, a new standard data type – Personal Status – that represents the “internal status” of a conversing human expressed with text, speech, face, and gesture. The same Personal Status data type is used by the machine to represent its own internal status as if it were a human.
Currently, Personal Status is composed of three Personal Status Factors:
- Emotion, the coded representation of the internal state resulting from the interaction of a human or avatar with the Environment or subsets of it, such as “Angry”, “Sad”, “Determined”.
- Cognitive State, the coded representation of the internal state reflecting the way a human or avatar understands the Environment, such as “Confused”, “Dubious”, “Convinced”.
- Social Attitude, the coded representation of the internal state related to the way a human or avatar intends to position vis-à-vis the environment, e.g., “Respectful”, “Confrontational”, “Soothing”.
Each Factor is represented by a standard set of labels and associated semantics with 2 tables:
- Table 1: Label Set contains descriptive labels relevant to the Factor in a three-level format:
- The CATEGORIES column specifies the relevant categories using nouns (e.g., “ANGER”).
- The GENERAL ADJECTIVAL column gives adjectival labels for general or basic labels within a category (e.g., “angry”).
- The SPECIFIC ADJECTIVAL column gives more specific (sub-categorised) labels in the relevant category (e.g., “furious”).
- Table 2: Label Semantics provides the semantics for each label in the GENERAL ADJECTIVAL and SPECIFIC ADJECTIVAL columns of the Label Set Table. For example, for “angry” the semantic gloss is “emotion due to perception of physical or emotional damage or threat.”
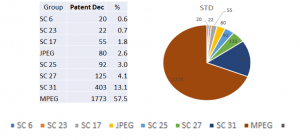
The mission of the international, unaffiliated, non-profit Moving Picture, Audio and Data Coding by Artificial Intelligence (MPAI) Standards Developing Organisation is to develop AI-enabled data coding standards. MPAI believes that its standards should enable humans to select machines whose internal operation they understand to some degree, rather than machines that are just “black boxes” resulting from unknown training with unknown data. Thus, an implemented MPAI standard breaks up monolithic AI applications, yielding a set of interacting components with identified data whose semantics is known, as far as possible. The AI Framework (MPAI-AIF) standards (html, pdf) specifies an environment where AI Workflows (AIW) composed of AI Modules (AIM) are executed in environments implemented as an AI Framework (AIF).
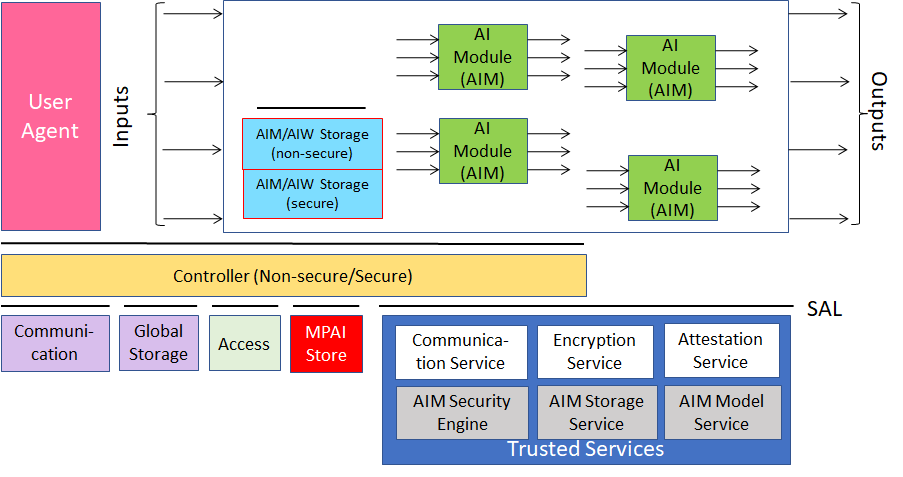
Figure 1 – Reference Model of AI Framework (AIF)
MPAI-MMC has defined two “Composite AI Modules (AIM)” that achieve the goal of representing the internal state of the conversing human and machine (or machine and machine). The first is called “Personal Status Extraction (PSE)” and is represented by Figure 2.
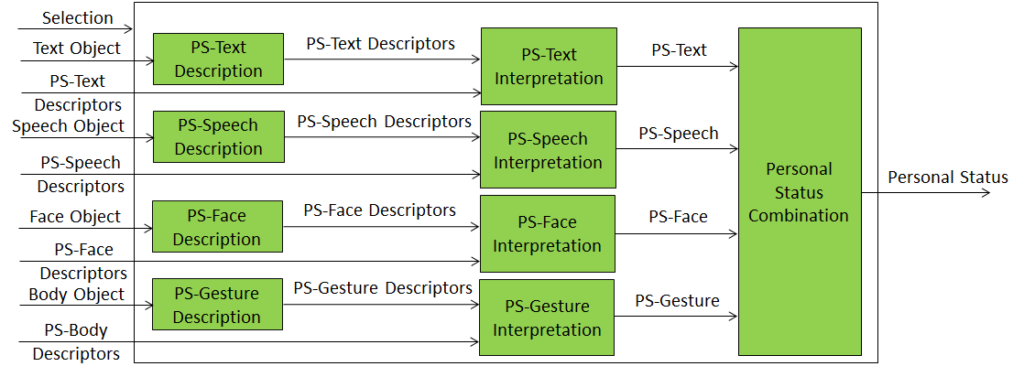
Figure 2 – Personal Status Extraction
PSE computes the Descriptors of each considered Modality – Text, Speech, Face, and Gesture. The Personal Status embedded in the Modality is obtained by interpreting the Modality Descriptors. The need of several MPAI Use Cases has suggested that Descriptors may be computed outside of the PSE and provided by another AIM, obviously with the same semantics. This is signalled by Input Selection. Personal Status Combination is an AIM that integrates the Personal Status of the four Modalities in a standard Personal Status Format.
The second Composite AIM – “Personal Status Display (PSD)” is used to convert the Text produced by the Machine with the associated Personal Status and is represented in Figure 3.
Figure 3 – Personal Status Display
Machine Text is passed as PSD output and synthesised as Speech using the Personal Status provided by PS-Speech. Face Descriptors are produced using Machine Speech and PS-Face. Body Descriptors are produced using Avatar Model, PS-Gesture, and Text. Avatar Descriptors, the combination of Face Descriptors and Body Descriptors are produced by the Avatar Description AIM. The ready-to-render Machine Avatar is produced by Avatar Synthesis.
Input Selection is used to indicate whether the PSD should produce Avatar Descriptors or ready-to-render Machine Avatar.
Let’s now see how the definition of the PSE and PSD Composite AIMs enables a compact representation of human-machine conversation use cases by considering the reference model of Conversation with Personal Status use case depicted in Figure 4.
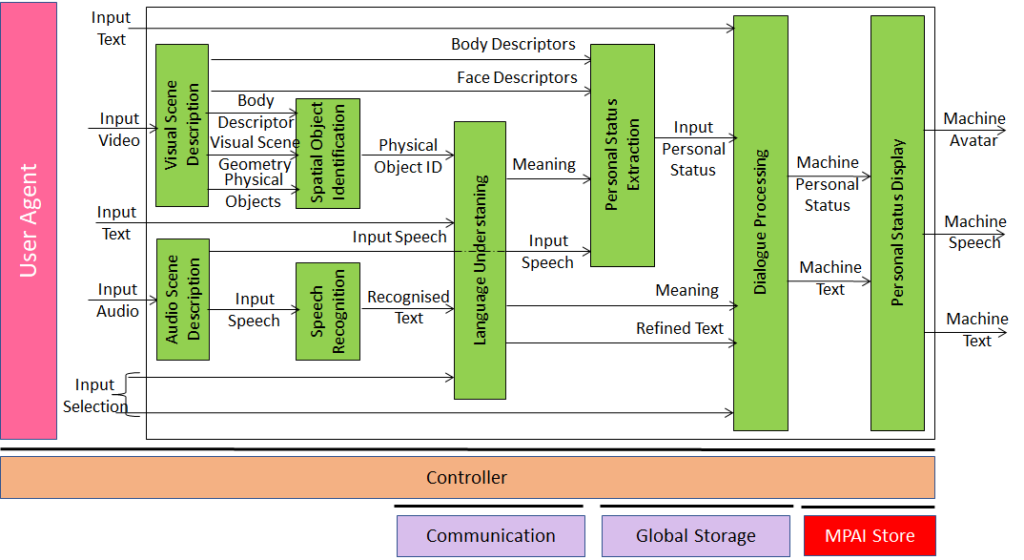
Figure 4 – Conversation with Personal Status
The visual frontend (Visual Scene Description) describes the visual scene providing the Descriptors of the Face and the Body of the human and a digital representation of the objects in the scene. The Audio frontend (Audio Scene Description) separates the speech from other sound sources. Spatial Object Identification analyses the arm, hand, and fingers of the human to identify which of the objects the human refers to in a conversation. Speech Recognition, Language Understanding, and Dialogue Processing are the usual elements of the conversation chain. In MPAI-MMC, however, Dialogue Processing deals with additional information in the form of Object ID and Personal Status of the human. Therefore, Dialogue Processing is requested not only to produce Machine Text in response to the human, but also its own Personal Status. Both Text and Personal Status are provided to the Personal Status Display Composite AIM that provides the full multimodal response as Machine Text, Machine Speech, and Machine Avatar.
What does Multimodal Conversion specify?
- Technologies required to analyse the text and/or the speech and other non-verbal components exchanged in human-machine and machine-machine conversation.
- Use Cases that apply the technologies:
- Conversation with Personal Status.
- Conversation with Emotion.
- Multimodal Question Answering.
- Conversation About a Scene.
- Human-CAV Interaction.
- Virtual Secretary for Videoconference
- Text and Speech Translation (one way, two ways, one to many)
Each Use Case normatively defines:
- The Functions of the AIW and (Composite) AIMs implementing the Use Case.
- The Connections between and among the AIMs.
- The Semantics and the Formats of the input and output data of the AIW and the AIMs.
- The JSON Metadata of the AIW.
Each AIM normatively defines:
- The Functions of the AIM.
- The Connections between and among the AIMs in case the AIM is Composite.
- The Semantics and the Formats of the input and output data of the AIMs.
- The JSON Metadata of the AIMs.
MPAI deals with all aspects of “AI-enabled Data Coding” in a unified way. Some of the data formats required by the MPAI-MMC Use Cases are specified by MPAI-MMC and some data formats by the standards produced by other MPAI groups. For instance, the Face and Body Descriptors are specified by the Avatar Representation and Animation standard and the “Spatial Object Identification” Composite AIM is specified by “Object and Scene Description” (MPAI-OSD).
The MPAI-MMC Version 2 Working Draft (html, pdf) is published with a request for Community Comments. Comments should be sent to the MPAI Secretariat by 2023/09/25T23:59 UTC. MPAI will use the Comments received to develop the final draft planned to be published at the 36th General Assembly (29 September 2023). An online presentation of the WD will be held on September 05 at 08 and 15 UTC. Register here for the 08 UTC and here for the 15 UTC presentations.