Standards and collaboration
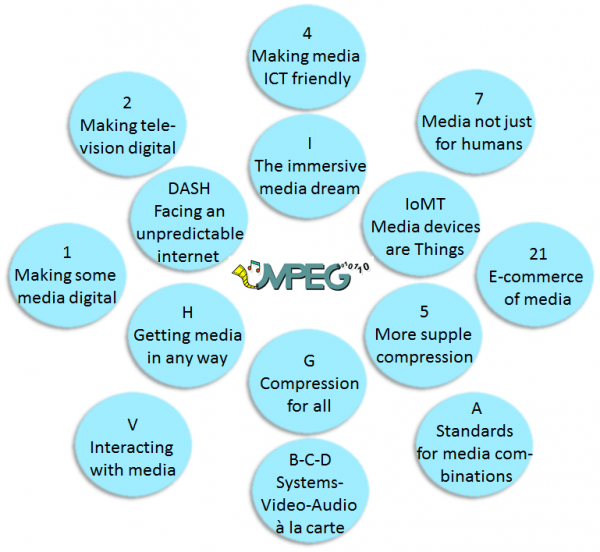
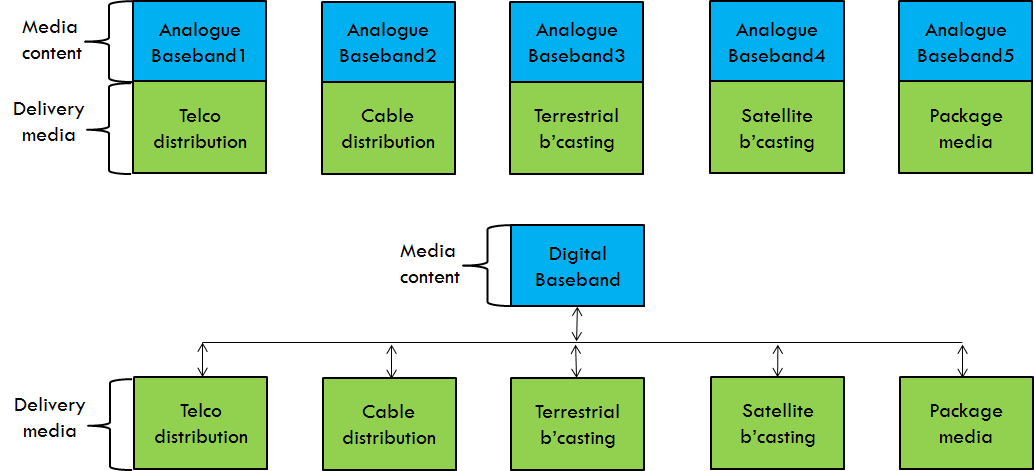
The hurdles of standardisation today Making standards is not like any other tasks. In most cases it is technical in nature because it is about agreeing on and documenting how certain things should be done to claim to be conforming to the standard. Standards can be developed unilaterally by someone powerful enough to tell other people how they should do things. More often, however, standards are developed collaboratively by people who share an interest in a standard, i.e. in enabling…