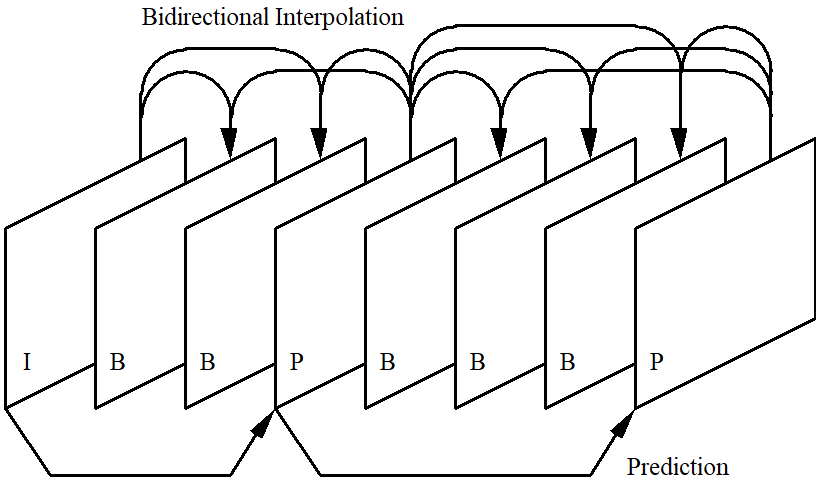
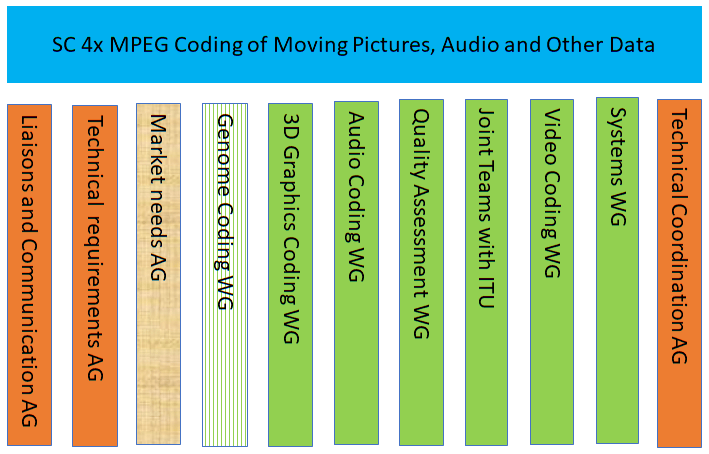
MPEG: vision, execution, results and a conclusion
Introduction In 1987, a few months before MPEG was the established, ISO TC 97 Data Processing became the ISO/IEC Joint Technical Committee 1 (JTC 1) on Information Technology. With this operation the data processing industry, renamed information technology industry on the occasion, was able to concentrate on a single Technical Committee (TC) all standardisation activities needed by that industry, including those “electrical”, until then the exclusive purview of IEC. Thirty-two years later, JTC 1 has become a very large TC,…