Introduction
Obviously, the electrical representation of sound information happened before the electrical representation of visual information and so did the services that used that representation to distribute sound information. The digital representation of audio, too, happened at different times than video’s. In the early 1980s the Compact Disc (CD) allowed record companies to distribute digital audio for the consumer market, while the D1 digital tape, available in the late 1980’s, was for the exclusive use of professional applications such as in the studio. Compression technologies reversed the order: compressed digital video happened before compressed digital audio by some 10 years. Therefore, unlike the title of the article Forty years of video coding and counting, the title of this post is Thirty years of audio coding and counting.
This statement can become a source of dispute, if a proper definition of Audio is not adopted. In this article by Audio we mean sound in the human audible range not generated by a human phonatory system or for any other sound source for which a sound production model is not available or not used. Indeed digital speech happened in professional applications (trunk network) some 20 years before the CD. ITU-T G.721 “32 kbit/s adaptive differential pulse code modulation (ADPCM)” dates back to 1984, the same year H.120 was approved as a recommendation.
Therefore the title of this article could very well have been Forty years of audio coding and counting. This would have come at the cost of a large number of speech compression standards and this article would have been overwhelmed by them. Therefore this article will only deal with audio compression standards where audio does not include speech. With one exception that will be mentioned later, I mean.
Unlike video compression where ITU-T is the non-MPEG body that develops video coding standards, in audio compression MPEG dominance is total. Indeed ITU-R, who does need audio compression for its digital audio broadcasting standards, prefers to rely on external sources, including MPEG.
MPEG-1 Audio
Those interested in knowing why and how a group – MPEG – working in video compression ended up also working on audio compression (and a few more other things) can look here. The kick off of the MPEG Audio group took place on 1-2 December 1988, when, in line with a tradition that at that time had not been fully established yet, a most diverse group of audio coding experts met in Hannover and kick-started the work that eventually gave rise to the MPEG-1 Audio standard released by MPEG in November 1992.
The Audio group in MPEG is very often the forerunner of things to come. In this instance the first is that while the broadcasting world shunned the low resolution MPEG-1 Video compression standard, it very much valued the MPEG-1 Audio compression standard. The second is that, unlike video, which relied on essentially the same coding architecture, the Audio Call for Proposals had yielded two classes of algorithms, one that was a well established, easy to implement but less performing and the other that was more recent, harder to implement (at that time) but more performing. The work to merge the two technologies was painstaking but eventually the standard included 3 layers (a notion later called profiles) where both technologies were used.
Layer 1 was used in Digital Compact Cassette (DCC), a product discontinued a few years later, Layer 2 was used in audio broadcasting and as the audio component of Video CD (VCD). Layer 3 (MP3) does not need a particular introduction ?. As revised in the subsequent MPEG-2 effort, MP3 provided a user experience with no perceivable difference as compared to the original CD signal for most content at 128 kbit/s from a CD source of 1.44 Mbit/s, i.e with a compression of 11:1.
MPEG-2 Audio
The main goal of this standard, approved in 1994, was multi-channel audio with the key requirement that an MPEG-1 Audio decoder should be able to decode a stereo component of an MPEG-2 Audio bitstream. Backward compatibility is particularly useful in the broadcasting world because an operator can upgrade to a multi-channel services without losing the customers who only have an MPEG-1 Audio decoder.
MPEG-2 AAC
Work on MPEG-2 Advanced Video Coding (AAC) was motivated by the request of those who wished to provide the best possible audio quality without backward compatibility constraints. This meant that layer 2 must decode both layer 1 and 2, and layer 3 must decode all layers. MPEG-2 AAC, released in April 1997, is built upon the MP3 technology and can provide perceptually transparent audio quality at 128 kbit/s for a stereo signal, and 320 kbit/s for a 5.1 channel signal (i.e. as in digital television).
MPEG-4 AAC
In 1998 MPEG-4 Audio was released with the other 2 MPEG-4 components – Systems and Visual. Again MPEG-4 AAC is built on MPEG-2 AAC. The dominating role of MP3 in music distribution was shaken in 2003 when Apple announced that its iTunes and iPod products would use MPEG-4 AAC as primary audio compression algorithm. Most PCs, smart phones and later tablets could play AAC songs. Far from using AAC as a pure player technology, Apple started the iTunes service that provides songs in AAC format packaged in the MPEG-4 File Format, with filename extension “.m4a”.
AAC-LD
In 1999 MPEG released MPEG-4 amendment 1 with a low delay version of AAC, called Low Delay AAC (AAC-LD). While a typical AAC encoder/decoder has a one-way latency of ~55 ms (transform delay plus look-ahead processing), AAC-LD achieves a one-way latency of only 21 ms by simplifying and replacing some AAC tools (new transform with lower latency and removal of look-ahead processing). AAC-LD can be used as a conversational codec, with a signal bandwidth and perceived quality of a music coder with excellent audio quality at 64 kb/s for a mono signal.
MPEG-4 HE-AAC
In 2003 MPEG released the MPEG-4 High Efficiency Advanced Audio Coding (HE-AAC), as amendment 1 to MPEG-4. HE-AAC helped to consolidate the role of the mobile handset as the tool of choice to access very good audio quality stereo music at 48 kbit/s, more than a factor of 2.5 better than AAC, for a compression ratio of almost 30:1 relative to the CD signal.
HE-AAC adds the spectral bandwidth replication (SBR) tool to the core AAC compression engine. Since AAC was already widely deployed, this permitted extending this base to HE-AAC by only adding the SBR tool to existing AAC implementations.
MPEG HE-AAC v2
In the same 2003, 9 months later, MPEG released the MPEG HE-AAC v2 profile. This originated from a tools contained in amendment 2 to MPEG-4 (Parametric coding for high-quality audio). While the core parametric coder did not enjoy wide adoption, the Parametric Stereo (PS) tool in the amendment could very efficiently encode stereo music as a mono signal plus a small amount of side-information. HE-AAC v2, the combination of PS tool with HE-AAC, enabled transmission of a stereo signal at 32 kb/s with very good audio quality.
This profile was also adopted by 3GPP under the name Enhanced aacPlus. Adoption by 3GPP paved the way for HE-AAC v2 technology to be incorporated into mobile phones. Today, more than 10 billion mobile devices support streaming and playout of HE-AAC v2 format songs. Since HE-AAC is built on AAC, these phone also support streaming and playout of AAC format songs.
ALS and SLS
In 2005 MPEG released two algorithms for lossless compression of audio, MPEG Audio LosslesS coding (ALS) and Scalable to LosslesS coding (SLS). Both provide perfect (i.e. lossless) reconstruction of a standard Compact Disk audio signal with a compression ratio approximately 2:1. An important feature of SLS is that it has a variable compression ratio: it can compress a stereo signal to 128 kb/s (11:1 compression ratio) with excellent quality as an AAC codec but it can achieve lossless reconstruction with a compression ratio of 2:1 by increasing the coded bitrate (i.e. by decreasing the compression ratio) in a continuous fashion.
MPEG Surround
ALS/SLS were the last significant standards in MPEG-4 Audio, which is MPEG’s most long-lived audio standard. First issued in 1999, 20 years later (in 2019) MPEG is issuing its Fifth Edition.
After “closing the MPEG-4 era”, MPEG created the MPEG-D suite of audio compression standards. The first of these was MPEG Surround, issued in 2007. This technology is a generalised PS of HE-AAC v2 tool in the sense that, MPEG Surround can operate as a 5-to-2 channel compression tool or as an M-to-N channel compression tool. This “generalised PS” tool is followed by a HE-AAC codec. Therefore MPEG Surround builds on HE-AAC as much as HE-AAC builds on AAC. MPEG Surround provides an efficient bridge between stereo and multi-channel presentations in low-bitrate applications. It has very good compression while maintaining very good audio quality and also low computational complexity. While HE-AAC can transmit stereo at 48 kbit/s, MPEG Surround can transmit 5.1 channel audio within the same 48 kbit/s transmission budget. The complexity is no greater than stereo HE-AAC’s. Hence MPEG Surround is a “drop-in” replacement for stereo services to extend them to 5.1 channel audio!
AAC-ELD
In 2007 MPEG released Enhanced Low Delay AAC (AAC-ELD) technology. This combines tools from other profiles: SBR and PS from HE-AAC v2 profile and AAC-LD. The new codec provides even greater signal compression with only a modest increase in latency: AAC-ELD provides excellent audio quality at 48 kb/s for a mono signal with a one-way latency of only 32 ms.
SAOC
In 2010 MPEG released MPEG-D Spatial Audio Object Coding (SAOC) which allows very efficient coding of a multi-channel signal that is a mix of objects (e.g. individual musical instruments). SAOC down-mixes the multi-channel signal, e.g. stereo to mono, codes and transmits the mono signal along with some side-information, and then up-mixes the received and decoded mono signal back to a stereo signal such that user perceives the instruments to be placed at the correct positions and the resulting stereo signal to be the same as the original. This is done by exploiting the fact that at any instant in time and any frequency region one of the instruments will tend to dominate the others so that in this time/frequency region the other signals will be perceived with much less acuity, if at all. SAOC analyses the input signal, divides each channel into time and frequency “tiles” and then decides to what extent each tile dominates. This is coded as side information.
An example SAOC application is teleconferencing, in which a multi-location conference call can be mixed at the conference bridge down to a single channel and transmitted to each conference participant, along with the SAOC side information. At the user’s terminal, the mono channel is up-mixed to stereo (or 3 channels – Left-Center-Right) and presented such that each remote conference participant is at a distinct location in the front sound stage.
USAC
Unified Speech and Audio Coding (USAC), released in 2011, combines the tools for speech coding and audio coding into one algorithm. USAC combines the tools from MPEG AAC (exploiting the means of human perception of audio) with the tools from a state-of-the-art speech coder (exploit the means of human production of speech). Therefore, the encoder has both a perceptual model and a speech excitation/vocal tract model and dynamically selects the music/speech coding tools every 20 ms. In this way USAC achieves a high level of performance for any input signal, be is music, speech or a mix of speech and music.
In the tradition of MPEG standards, USAC extends the range of “good” performance down to as low as 16 kb/s for a stereo signal and provides higher quality as the bitrate is increased. The quality at 128 kbit/s for a stereo signal is slightly better that MPEG-4 AAC so USAC can replace AAC, because its performance is equal or better than AAC at all bit rates. USACcan similarly code multichannel audio signals, and can also optimally encode speech content.
DRC
MPEG-D Dynamic Range Control (DRC) is a technology that gives the listener the ability to control the audio level. It can be a post-processor for every MPEG audio coding technology and modifies the dynamic range of the decoded signal as it is being played. It can be used to reduce the loudest part of a movie so as not to disturb your neighbours, to make the quiet portions of the audio louder in hostile audio environments (car, bus, room with many people), to match the dynamics of the audio to that of a smart phone speaker output, which typically has very limited dynamic range. The DRC standard also plays the very important function of normalizing the loudness of the audio output signal, which may be mandated in some regulatory environments. DRC was released in 2015 and extended in 2017 as Amendment 1 Parametric DRC, gain mapping and equalization tools.
3D Audio
MPEG-H 3D Audio, released in 2015, is part of the typical suite of MPEG tools: Systems, Video and Audio. It provides very efficient coding of immersive audio content, typically from 11 to 22 channels of content. The 3D Audio algorithms can actually process any mix of channels, objects and Higher Order Ambisonics (HOA) content, where objects are single-channel audio whose position can be dynamic in time and HOA can encode an entire sound scene as a multi-channel “HOA coefficient” signal.
Since 3D Audio content is immersive, it is conceived as being consumed as a 360-degree “movie” (i.e. video plus audio). The user sits at the center of a sphere (“sweet spot”) and the audio is decoded and presented so that the user perceives it to be coming from somewhere on the surrounding sphere. MPEG-H 3D audio also can be presented via headphones because not every consumer has an 11 or 22 channel listening space. Moreover MPEG-H 3D Audio supports use of a default or personalised Head Related Transfer Function (HRTF) to allow the listener to perceive the audio content as if it is from sources all around the listener, just as it would be when using loudspeakers. An added feature of 3D Audio playout to headphones, is that the audio heard by the listener can remain at the “correct” position when the user turns his or her head. In other words, a sound that is “straight ahead” when the user is looking straight ahead is perceived as coming from the left if the user turns to look right. Hence, MPEG-H 3D Audio is already a nearly complete solution for Video 360 applications.
Immersive Audio
This activity (to be released as a standard sometime in 2021) is part of the emerging MPEG-I Immersive Audio standard. MPEG is still defining the requirements and functionality of this standard, which will support audio in Virtual and Augmented Reality applications. It will be based on MPEG-H 3D Audio, which already supports a 360 degree view of a virtual world from one listener position (“3 degrees of freedom” or 3DoF) that the listener can move his or her head left, right, up, down or tilted left or right (so-called “yaw, pitch roll”). The Immersive Audio standard will add three additional degrees of freedom, i.e., permit the user to get up and walk around in the Virtual World. This additional movement is designated “x, y, z,” so that MPEG-I Immersive Audio supports 6 degrees of freedom (6 DoF) which are “yaw, pitch roll and x, y, z.” It is envisioned that MPEG-I Immersive Audio will use MPEG-H 3D Audio to compress the audio signals, and will specify additional metadata and technology so that the audio signals can be rendered in a fully flexible 6 DoF way.
Conclusions
MPEG is proud of the work done by the Audio group. For 30 years the group has injected generations of audio coding standards into the market. In the best MPEG tradition, the standards are generic in the sense that can be used in audio-only or audio+video applications and often scalable, with a new generation of audio coding standards building on previous ones.
This long ride is represented in the figure that ventures into the next step of the ride.
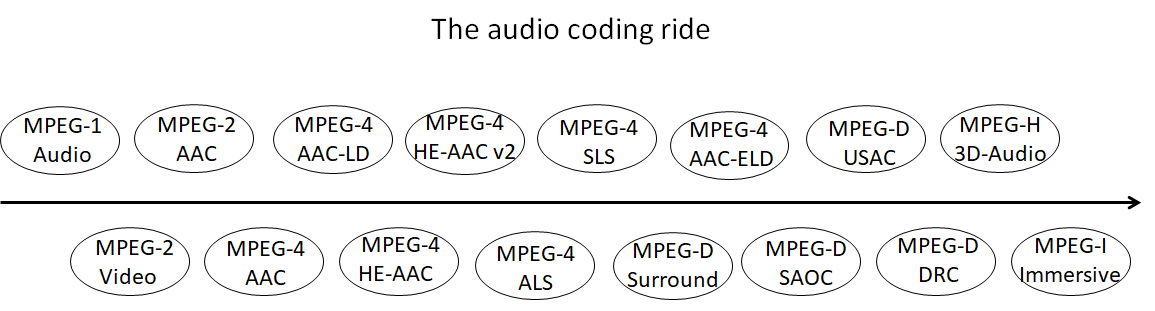
Today MPEG Audio already provides a realistic 3DoF experience in combination with MPEG Video standards. More will be needed to provide a complete and rewarding 6DoF experience, but MPEG’s ability to draw the necessary multi-domain expertise from its membership promises that the goal will be successfully achieved.
Acknowledgements
This article would not have been possible without the competent assistance – and memory – of Schuyler Quackenbush, the MPEG Audio Chair.
Posts in this thread (in bold this post)
- Thirty years of audio coding and counting
- Is there a logic in MPEG standards?
- Forty years of video coding and counting
- The MPEG ecosystem
- Why is MPEG successful?
- MPEG can also be green
- The life of an MPEG standard
- Genome is digital, and can be compressed
- Compression standards and quality go hand in hand
- Digging deeper in the MPEG work
- MPEG communicates
- How does MPEG actually work?
- Life inside MPEG
- Data Compression Technologies – A FAQ
- It worked twice and will work again
- Compression standards for the data industries
- 30 years of MPEG, and counting?
- The MPEG machine is ready to start (again)
- IP counting or revenue counting?
- Business model based ISO/IEC standards
- Can MPEG overcome its Video “crisis”?
- A crisis, the causes and a solution
- Compression – the technology for the digital age
- On my Charles F. Jenkins Lifetime Achievement Award
- Standards for the present and the future