The question looks innocent enough. A video is a sequence of images (called frames) captured and eventually displayed at a given frequency. However, by stopping at a specific frame of the sequence, a single video frame, i.e. an image, is obtained.
If we talk of a sequence of video frames, that would always be true. It would also be true if an image compression algorithm (an “intra-frame” coding system) is applied to each individual frame. Such coding system may not give an exciting compression ratio, but can serve very well the needs of some applications, for instance those requiring the ability to decode an image using just one compressed image. This is the case of Motion JPEG (now largely forgotten) and Motion JPEG 2000 (used for movie distribution and other applications) or some profiles of MPEG video coding standards used for studio or contribution applications.
If the application domain requires more powerful compression algorithms, the design criteria are bound to be different. Interframe video compression that exploits the redundancy between frames must be used. In general, however, if video is compressed using an interframe coding mode, a single frame may very well not be an image because its pixels may have been encoded using pixels of some other frames. This can be seen in the image below dating back 30 years ago in MPEG-1 times.
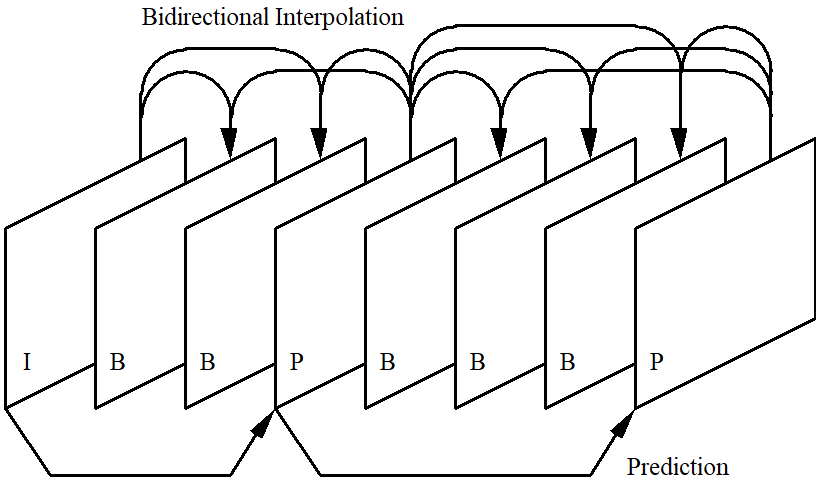
The first image (I-picture) at the left is compressed using only the pixels in the image. The fourth one (P-picture) is predictively encoded starting from the I-Picture. The second and third image (B-pictures) are interpolated using the first and the fourth. This continue in the next frames where the sequence can be P-B-B-B-P where the last P-picture is predicted from the first P-picture and 3 interpolated pictures (B-pictures) are created from the first and the last P pictures.
All MPEG intraframe coding schemes – MPEG-1, MPEG-2, MPEG-4 Visual and AVC, MPEG-H (HEVC), and MPEG-I (VVC) – have intraframe encoded pictures. This is needed because in broadcasting applications the time it takes for a decoder to “tune-in” must be as short as possible. Having an intra-coded picture, say, every half a second or every second, is a way to achieve that. Having intra-coded pictures is also helpful in interactive applications where the user may wish to jump anywhere in a video.
Therefore, some specific video frames in an interframe coding scheme can be images.
Why don’t we make the algorithms for image coding and intra-coded pictures of an interframe coding scheme the same?
We could but this has never been done for several reasons
- The intra-coding mode is a subset of a general interframe video coding scheme. Such schemes are rather complex, over the years many coding tools have been designed and when the intraframe coding mode is designed some tools are used because “they are already there”.
- Most applications employing an interframe coding scheme have strict real time decoding requirements. Hence complexity of decoding tools plays a significantly more critical role in an interframe coding scheme than in a still picture coding scheme.
- A large number of coding tools in an interframe video coding scheme are focused on motion-related processing.
- Due to very large data collected in capturing video than capturing images, the impact of coding efficiency improvement is different.
- Real time delivery requirements of coded video have led MPEG to develop significantly different System Layer technologies (e.g. DASH) and make different compromises at the system layer.
- Comparisons between the performance of the still picture coding mode of the various interframe coding standards with available image coding standards have not been performed in an environment based on a design of tests agreed among experts from all areas.
- There is no proven need or significant benefit of forcing the still picture coding mode of an MPEG scheme to be the same as any image compression standard developed by JPEG or vice-versa.
There is no reason to believe that this conclusion will not be confirmed in future video coding systems. So why are there several image compression schemes that have no relationship with video coding systems? The answer is obvious: the industry that needs compressed images is different than the industry that needs compressed video. The requirements of the two industries are different and, in spite of the commonality of some compression tools, the specification of the image compression schemes and of the video compression schemes turn out to be different and incompatible.
One could say that the needs of traditional 2D image and video are well covered by existing standards, But what about new technologies that enable immersive 2D visual experiences?
One could take a top-down philosophical approach. This is intellectually rewarding but technology is not necessarily progressing following a rational approach. The alternative is to take a bottom-up experiential approach. MPEG has constantly taken the latter approach and, in this particular case, it acts in two directions:
- Metadata for Immersive Video (MIV). This representsa dynamic immersive visual experience with 3 streams of data: Texture, Depth and Metadata. Texture information is obtained by suitably projecting the scene on a series of suitably selected planes. Texture and Depth are currently encoded with HEVC.
- Point Clouds with a large number of points can efficiently represent immersive visual content. Point clouds are projected on a fixed number of planes and projections can be encoded using any video codec.
Both #1 and #2 coding schemes include the equivalent of video intra-coded pictures. As for video, these are designed using the tools that exist in the equivalent of video inter-coded pictures.
Posts in this thread
- What is the difference between an image and a video frame?
- MPEG and JPEG are grown up
- Standards and collaboration
- The talents, MPEG and the master
- Standards and business models
- On the convergence of Video and 3D Graphics
- Developing standards while preparing the future
- No one is perfect, but some are more accomplished than others
- Einige Gespenster gehen um in der Welt – die Gespenster der Zauberlehrlinge
- Does success breed success?
- Dot the i’s and cross the t’s
- The MPEG frontier
- Tranquil 7+ days of hard work
- Hamlet in Gothenburg: one or two ad hoc groups?
- The Mule, Foundation and MPEG
- Can we improve MPEG standards’ success rate?
- Which future for MPEG?
- Why MPEG is part of ISO/IEC
- The discontinuity of digital technologies
- The impact of MPEG standards
- Still more to say about MPEG standards
- The MPEG work plan (March 2019)
- MPEG and ISO
- Data compression in MPEG
- More video with more features
- Matching technology supply with demand
- What would MPEG be without Systems?
- MPEG: what it did, is doing, will do
- The MPEG drive to immersive visual experiences
- There is more to say about MPEG standards
- Moving intelligence around
- More standards – more successes – more failures
- Thirty years of audio coding and counting
- Is there a logic in MPEG standards?
- Forty years of video coding and counting
- The MPEG ecosystem
- Why is MPEG successful?
- MPEG can also be green
- The life of an MPEG standard
- Genome is digital, and can be compressed
- Compression standards and quality go hand in hand
- Digging deeper in the MPEG work
- MPEG communicates
- How does MPEG actually work?
- Life inside MPEG
- Data Compression Technologies – A FAQ
- It worked twice and will work again
- Compression standards for the data industries
- 30 years of MPEG, and counting?
- The MPEG machine is ready to start (again)
- IP counting or revenue counting?
- Business model based ISO/IEC standards
- Can MPEG overcome its Video “crisis”?
- A crisis, the causes and a solution
- Compression – the technology for the digital age