Introduction
In a technology space moving at an accelerated pace like the one MPEG has the task to develop standards for, it is difficult to have a clear plan for the future (MPEG has a 5-year plan, though).
Still, when MPEG was developing the Multimedia Linking Application Format (MLAF), it “discovered” that it had developed or was developing several standards – MPEG-7, Compact descriptors for visual search (CDVS), Compact descriptors for video analysis (CDVA) and Media Orchestration.
The collection of these standards (and of others in the early phases of conception or development, e.g. Neural Network Compression and Video Coding for Machines) that help create the Multimedia Linking Environment, i.e. an environment where it is possible to create a link between a given spatio-temporal region of a media object and spatio-temporal regions in other media objects.
This article explains the benfits brought by the MLAF “multimedia linking” standard also for very concrete applications.
Multimedia Linking Environment
Until a quarter of century ago, virtually the only device that could establish relationships between different media items was the brain. A very poor substitute was a note on a book to record a possible relationship of the place in the book where the note was written with content in the same or different books.
The possibility to link a place in a web page to another place in another web page, or to a media object, was the great innovation brought by the web. However, a quarter of century after a billion web sites and quadrillions of linked web pages, we must recognise that the notion of linking is pervasive one and not necessarily connected with the web.
MPEG has dedicated significant resources to the problem described by the sentence “I have a media object and I want to know which other related media objects exist in a multimedia data base” and represented in the MPEG-7 model depicted the figure below.
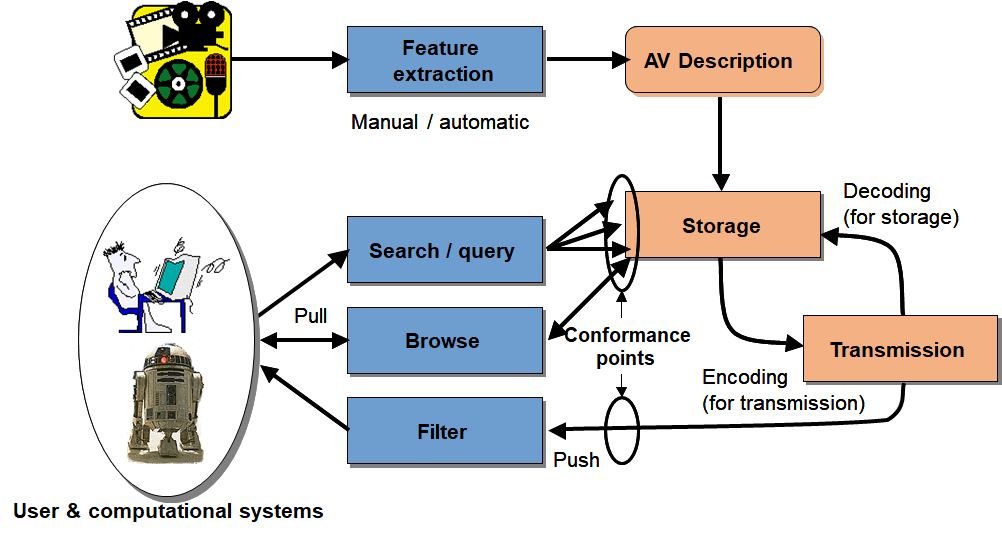
However, MPEG-7 is an instance of the more general problem of linking a given spatio-temporal region of a media object to spatio-temporal regions in other media objects.
These are some examples:
- A synthetic object is created out of a number of pictures of an object. There is a relationship between the pictures and the synthetic object;
- There is a virtual replica of a physical place. There is a relationship between the physical place and the virtual replica;
- A User is experiencing as virtual place in a virtual reality application. There is a relationship between the two virtual places;
- A user creates a media object by mashing up a set of media items coming from different sources. There is a relationship between the media items and the mashed up media object.
MPEG has produced MPEG-A part 16 (Media Linking Application Format – MLAF) specifies a data format called bridget that can be used to link any kinds of media. MPEG has also developed a number of standards that play an auxiliary role in the “ media linking” context outlined by the examples above.
- MPEG-7 parts 1 (Systems), 3 (Visual), 4 (Audio) and 5 (Multimedia) provide the systems elements, and the visual (image and video), audio and multimedia descriptions.
- MPEG-7 parts 13 (Compact descriptors for visual search) and 15 (Compact descriptors for video analysis) provide new generation image and video descriptors
- MPEG-B part 13 (Media Orchestration) provides the means to mash up media items and other data to create personal user experiences.
The MLAF standard
A bridget is a link between a “source” content and a “destination” content. It contains information on
- The source and the destination content
- The link between the two
- The information in the bridget is presented to the users who consume the source content.
The last information is the most relevant to the users because it is the one that enables them to decide whether the destination content is of interest to them.
The structure of the MLAF representation (points 1 and 2) is based on the MPEG-21 Digital Item Container implemented as a specialised MPEG-21 Annotation. The spatio-temporal scope is represented by the expressive power of two MPEG-7 tools and the general descriptive capability of the MPEG-21 Digital Item. They allow a bridget author to specify a wide range of possible associations and to be as precise and granular as needed.
The native format to present bridget information is based on MPEG-4 Scene description and application engine. Nevertheless, a bridget can be directly linked to any external presentation resource (e.g., an HTML page, an SVG graphics or others).
Bridgets for companion screen content
An interesting application of the MLAF standard is described in the figure below describing the entire bridget workflow.
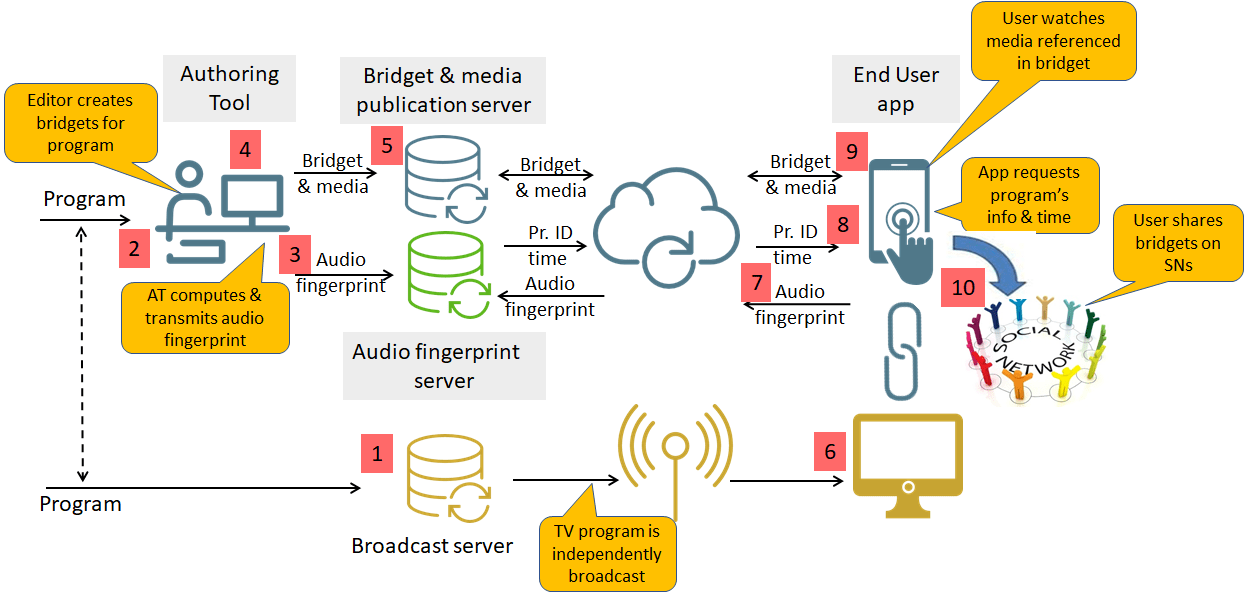
- A TV program, scheduled to be broadcast at a future time, is uploaded to the broadcast server [1] and to the bridget Authoring Tool (BAT) [2].
- BAT computes and stores the program’s audio fingerprints to the Audio Fingerprint Server (AFS) [3].
- The bridget editor uses BAT to create bridgets [4].
- When the editor is done all bridgets of the program and the referenced media objects are uploaded to the Publishing Server [5].
- At the scheduled time, the TV program is broadcast [6].
- The end user’s app computes the audio fingerprint and sends it to the Audio Fingerprint Server [7].
- AFS sends to the user’s app ID and time of the program the user is watching [8].
- When the app alerts the user that a bridget is available, the viewer may decide to
- Turn his eyes away from the TV set to her handset
- Play the content in the bridget [9]
- Share the bridget to a social network [10].
This is the workflow of a recorded TV program. A similar scenario can be implemented for live programs. In this case bridgets must be prepared in advance so that the publisher can select and broadcast a specific bridget when needed.
Standards are powerful tools that facilitate the introduction of new services, such as companion screen content. In this example, the bridget standard can stimulate the creation of independent authoring tools and end-user applications.
Creating bridgets
The bridget creation workflow depends on the types of media object the bridget represents.
Let’s assume that the bridget contains different media types such as an image, a textual description, an independently selectable sound track (e.g. an ad) and a video. Let’s also assume that the layout of the bridget has been produced beforehand.
This is the sequence of steps performed by the bridget editor:
- Select a time segment on the TV program timeline and a suitable layout
- Enter the appropriate text
- Provide a reference image (possibly taken from the video itself)
- Find a suitable image by using an automatic images search tool (e.g. based on the CDVS standard)
- Provide a reference video clip (possibly taken from the video itself)
- Find a suitable video clip, possibly taken from the video itself, by using an automatic video search tool (e.g. based on the CDVA standard)
- Add an audio file.
The resulting bridget will appears to the end user like this.
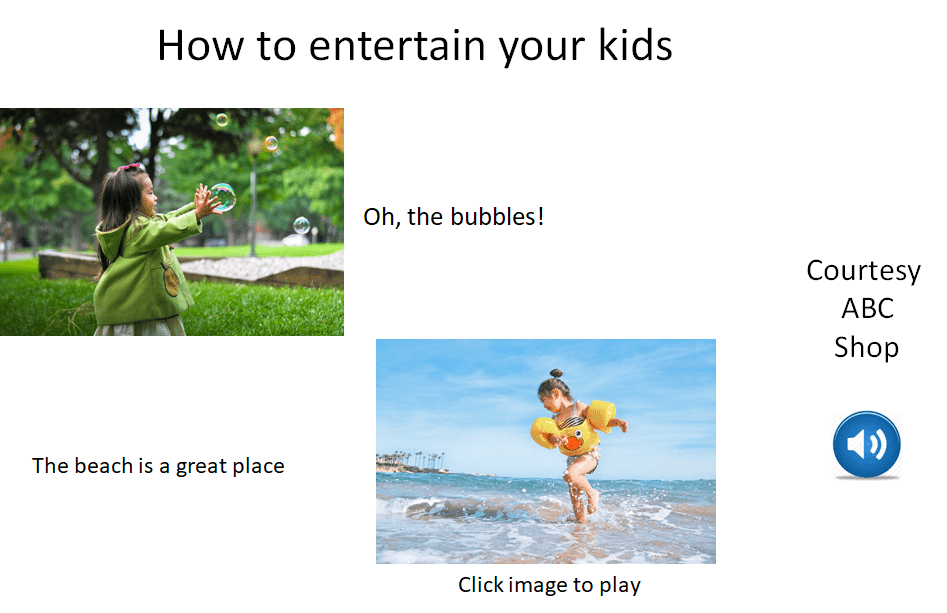
When all bridgets are created, the editor saves the bridgets and the media to the publishing server.
It is clear that the “success” of a bridget (in terms of number of users who open it) depends to a large extent on how the bridget is presented.
Why bridgets
Bridget was the title of a research project funded by the 7th Framework Research Program of the European Commission. The MLAF standard (ISO/IEC 23000-16) was developped at the instigation and with participation of members of the Bridget project.
At this page you will find more information on how the TVBridge application can be used to create, publish and consume bridgets for recorded and live TV programs.
Posts in this thread
- Media, linked media and applications
- Standards and quality
- How to make standards adopted by industry
- MPEG status report (Jan 2020)
- MPEG, 5 years from now
- Finding the driver of future MPEG standards
- The true history of MPEG’s first steps
- Put MPEG on trial
- An action plan for the MPEG Future community
- Which company would dare to do it?
- The birth of an MPEG standard idea
- More MPEG Strengths, Weaknesses, Opportunities and Threats
- The MPEG Future Manifesto
- What is MPEG doing these days?
- MPEG is a big thing. Can it be bigger?
- MPEG: vision, execution,, results and a conclusion
- Who “decides” in MPEG?
- What is the difference between an image and a video frame?
- MPEG and JPEG are grown up
- Standards and collaboration
- The talents, MPEG and the master
- Standards and business models
- On the convergence of Video and 3D Graphics
- Developing standards while preparing the future
- No one is perfect, but some are more accomplished than others
- Einige Gespenster gehen um in der Welt – die Gespenster der Zauberlehrlinge
- Does success breed success?
- Dot the i’s and cross the t’s
- The MPEG frontier
- Tranquil 7+ days of hard work
- Hamlet in Gothenburg: one or two ad hoc groups?
- The Mule, Foundation and MPEG
- Can we improve MPEG standards’ success rate?
- Which future for MPEG?
- Why MPEG is part of ISO/IEC
- The discontinuity of digital technologies
- The impact of MPEG standards
- Still more to say about MPEG standards
- The MPEG work plan (March 2019)
- MPEG and ISO
- Data compression in MPEG
- More video with more features
- Matching technology supply with demand
- What would MPEG be without Systems?
- MPEG: what it did, is doing, will do
- The MPEG drive to immersive visual experiences
- There is more to say about MPEG standards
- Moving intelligence around
- More standards – more successes – more failures
- Thirty years of audio coding and counting
- Is there a logic in MPEG standards?
- Forty years of video coding and counting
- The MPEG ecosystem
- Why is MPEG successful?
- MPEG can also be green
- The life of an MPEG standard
- Genome is digital, and can be compressed
- Compression standards and quality go hand in hand
- Digging deeper in the MPEG work
- MPEG communicates
- How does MPEG actually work?
- Life inside MPEG
- Data Compression Technologies – A FAQ
- It worked twice and will work again
- Compression standards for the data industries
- 30 years of MPEG, and counting?
- The MPEG machine is ready to start (again)
- IP counting or revenue counting?
- Business model based ISO/IEC standards
- Can MPEG overcome its Video “crisis”?
- A crisis, the causes and a solution
- Compression – the technology for the digital age